本文共 97379 字,大约阅读时间需要 324 分钟。
面试过不少前端从业者,简历写的平平淡淡,别人会的技能他也都会,看起来什么都掌握一些;有些会请过来当面聊一下,有些就直接拒绝了(如果是公司内要求独立完成项目的岗位,简历里放很多学习时候的DEMO项目,没有真实上线的项目,这种简历一般都会拒绝掉)。
当我们去一家公司面试,面试官有很大的主动权,面试官属于攻击方,求职者属于防守方,我们不可能什么方向都研究的非常深,所以扬长避短是最好的方式,推荐大家要做帐篷型的人,而不是水桶型的人;市场上岗位非常多,我们需要做的就是找到适合自己长处发展的那个职业!
面试的时候一定不要和面试官硬刚,可以适度的夸大自己,但是一定不要以为自己技术牛,就疯狂装B;面试官非常希望找到和自己脾气相投的人一起共事,哪怕你真的是万里挑一的大牛,面试官感觉和你一起共事非常不舒服,那么拒绝你也不是什么太难的决定。
如果遇到自己期望薪资内的offer,一定不要犹豫,直接答应下来,但是入职的时间,可以稍微向后推一下,可以一个礼拜后,十天后等,这段时间再继续面试,这时候薪资就一定要找高于自己答应offer的薪资,如果期间遇到自己更加满意的offer,就在自己答应的offer里找一家自己最感兴趣的入职。
目录

HTML 面试题
HTML5 有哪些新特性?
答:1.HTML4 规定了三种声明方式,分别是:严格模式、过渡模式 和 框架集模式;
而HTML5因为不是SGML的子集,只需要<!DOCTYPE>就可以了:
2.语义化更好的内容标签。header/footer/article等
3.音频、视频 API(audio,video)
4.表单控件:
HTML5 拥有多个新的表单输入类型。这些新特性提供了更好的输入控制和验证。
- color
- date
- datetime
- datetime-local
- month
- number
- range
- search
- tel
- time
- url
- week
5.5个API-本地存储,长期存储数据的 localStorage,比较常用,临时存储的 sessionStorage,浏览器关闭后自动删除,实际工作中使用的场景不多。
画布/Canvas,canvas,figure,figcaption.
地理/Geolocation.地理位置 API 允许用户向 Web 应用程序提供他们的位置。出于隐私考虑,报告地理位置前会先请求用户许可。
拖拽释放.HTML拖拽释放 (Drag and drop) 接口使应用程序能够在浏览器中使用拖放功能。例如,通过这些功能,用户可以使用鼠标选择可拖动元素,将元素拖动到可放置元素,并通过释放鼠标按钮来放置这些元素。可拖动元素的一个半透明表示在拖动操作期间跟随鼠标指针。
Web Workers.webworker, websocket, Geolocation,当在 HTML 页面中执行脚本时,页面的状态是不可响应的,直到脚本已完成。web worker 是运行在后台的 JavaScript,独立于其他脚本,不会影响页面的性能。您可以继续做任何愿意做的事情:点击、选取内容等等,而此时 web worker 在后台运行。
?
答:
- ⻚⾯被加载的时, link 会同时被加载,⽽ @imort ⻚⾯被加载的时, link 会同时被加
- 载,⽽ @import 引⽤的 CSS 会等到⻚⾯被加载完再加载 import 只在 IE5 以上才能识
- 别,⽽ link 是 XHTML 标签,⽆兼容问题 link ⽅式的样式的权重 ⾼于 @import 的权
- 重
<!DOCTYPE>声明位于⽂档中的最前⾯,处于<html>标签之前。告知浏览器的解析器, ⽤什么⽂档类型 规范来解析这个⽂档- 严格模式的排版和 JS 运作模式是 以该浏览器⽀持的最⾼标准运⾏
- 在混杂模式中,⻚⾯以宽松的向后兼容的⽅式显示。模拟⽼式浏览器的⾏为以防⽌站点⽆法⼯作。 DOCTYPE 不存在或格式不正确会导致⽂档以混杂模式呈现
如何实现浏览器内多个标签页之间的通信?
调用 localstorge、cookies 等本地存储方式;
- 1、在 B 页面中可以使用 window.opener 获得 A 页面的 window 句柄,使用该句柄即可调用 A 页面中的对象,函数等。
- 例如 A 页面定义 js 函数 onClosePageB,在 B 页面可以用 window.opener.onClosePageB 来进行回调。
- 2、使用
window.showModalDialog(sURL [, vArguments] [,sFeatures])打开新窗口。 其中 vArguments 参数可以用来向对话框传递参数。传递的参数类型不限,包括数组、函数等。对话框通过window.dialogArguments来取得传递进来的参数。 - 3、如果是支持 HTML5 的话,建议用本地存储 (local storage),它支持一个事件方法 window.onstorage,只要其中一个窗口修改了本地存储,其他同源窗口会触发这个事件。
总结:
- WebSocket、SharedWorker;
- 也可以调用 localstorge、cookies 等本地存储方式;
- localstorge 另一个浏览上下文里被添加、修改或删除时,它都会触发一个事件,
- 我们通过监听事件,控制它的值来进行页面信息通信;
- 注意 quirks:Safari 在无痕模式下设置 localstorge 值时会抛出 QuotaExceededError 的异常;
方法一:调用 localstorge
标签1:
标签2:
$(function(){ window.addEventListener("storage", function(event){ console.log(event.key + "=" + event.newValue); }); //使用storage事件监听添加、修改、删除的动作}); 将要传递的信息存储在 cookie 中,每隔一定时间读取 cookie 信息,即可随时获取要传递的信息。
标签1:
$(function(){ $("#btn").click(function(){ var name=$("#name").val(); document.cookie="name="+name; });}); 标签2:
$(function(){ function getCookie(key) { return JSON.parse("{\"" + document.cookie.replace(/;\s+/gim,"\",\"").replace(/=/gim, "\":\"") + "\"}")[key]; } setInterval(function(){ console.log("name=" + getCookie("name")); }, 10000);}); ⾏内元素有哪些?块级元素有哪些? 空(void)元素有那些?⾏内元 素和块级元素有什么区别?
答:
- ⾏内元素有: a b span img input select strong
- 块级元素有: div ul ol li dl dt dd h1 h2 h3 h4… p
- 空元素: br,hr img input link meta
- ⾏内元素不可以设置宽⾼,不独占⼀⾏
- 块级元素可以设置宽⾼,独占⼀⾏
简述⼀下src与href的区别?
答:
- src ⽤于替换当前元素,href⽤于在当前⽂档和引⽤资源之间确⽴联系。
- src 是 source 的缩写,指向外部资源的位置,指向的内容将会嵌⼊到⽂档中当前标签所在位置;在请求 src 资源时会将其指向的资源下载并应⽤到⽂档内,例如 js 脚本,img 图⽚和 frame 等元素
<script src ="js.js"></script>当浏览器解析到该元素时,会暂停其他- 资源的下载和处理,直到将该资源加载、编译、执⾏完毕,图⽚和框架等元素
- 也如此,类似于将所指向资源嵌⼊当前标签内。这也是为什么将js脚本放在底
- 部⽽不是头部
- href 是 Hypertext Reference 的缩写,指向⽹络资源所在位置,建⽴和当前元素(锚点)或当前⽂档(链接)之间的链接,如果我们在⽂档中添加
<link href="common.css" rel="stylesheet"/>那么浏览器会识别该⽂档为 css ⽂件,就会并⾏下载资源并且不会停⽌对当前⽂档的处理。这也是为什么建议使⽤ link ⽅式来加载 css ,⽽不是使⽤ @import ⽅式
cookies,sessionStorage,localStorage 的区别?
答:
- cookie 是网站为了标示用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。
- cookie 数据始终在同源的 http 请求中携带(即使不需要),记会在浏览器和服务器间来回传递。
- sessionStorage 和 localStorage 不会自动把数据发给服务器,仅在本地保存。
存储大小
- cookie 数据大小不能超过 4k。
- sessionStorage 和 localStorage 虽然也有存储大小的限制,但比 cookie 大得多,可以达到 5M 或更大。
有期时间
- localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
- sessionStorage 数据在当前浏览器窗口关闭后自动删除。
- cookie 设置的 cookie 过期时间之前一直有效,即使窗口或浏览器关闭
HTML5 的离线储存的使用和原理?
答:
相似存储
localStorage 长期存储数据,浏览器关闭后数据不丢失; sessionStorage 数据在浏览器关闭后自动删除。
离线的存储
两种方式
- HTML5 的离线存储
.appcache文件【废弃】 service-worker的标准
HTML5 的离线存储.appcache文件【废弃】
在用户没有与因特网连接时,可以正常访问站点或应用,在用户与因特网连接时,更新用户机器上的缓存文件。
原理:HTML5 的离线存储是基于一个新建的。appcache 文件的缓存机制(不是存储技术),通过这个文件上的解析清单离线存储资源,这些资源就会像 cookie 一样被存储了下来。
之后当网络在处于离线状态下时,浏览器会通过被离线存储的数据进行页面展示。
如何使用
- 1、页面头部像下面一样加入一个 manifest 的属性
-
2、在 cache.manifest 文件的编写离线存储的资源
CACHE MANIFEST#v0.11CACHE:js/app.jscss/style.cssNETWORK:resourse/logo.pngFALLBACK:/ /offline.html
-
3、在离线状态时,操作 window.applicationCache 进行需求实现。
service-worker
可以参考
怎样处理 移动端 1px 被 渲染成 2px 问题?
答:
meta 标签中的 viewport 属性 ,initial-scale 设置为 1
rem 按照设计稿标准走,外加利用 transfrome 的 scale(0.5) 缩小一倍即可; 2 全局处理
meta 标签中的 viewport 属性 ,initial-scale 设置为 0.5
rem 按照设计稿标准走即可
解释
UI 设计师设计的时候,画的 1px(真实像素)实际上是 0.5px(css) 的线或者边框。但是他不这么认为,他认为他画的就是 1px 的线,因为他画的稿的尺寸本身就是屏幕尺寸的 2 倍。假设手机视网膜屏的宽度是 320x480 宽,但实际尺寸是 640x960 宽,设计师设计图的时候一定是按照 640x960 设计的。但是前端工程师写代码的时候,所有 css 都是按照 320x480 写的,写 1px(css),浏览器自动变成 2px(真实像素)。
那么前端工程师为什么不能直接写 0.5px(css) 呢?因为在老版本的系统里写 0.5px(css) 的话,会被浏览器解读为 0px(css),就没有边框了。所以只能写成 1px(css),实际在屏幕上显示出来就是设计师画的 1px(真实像素)的 2 倍那么宽,所以设计师会觉得这个线太粗了,和他的设计稿不一样。在新版的系统里,已经开始逐渐支持 0.5px(css) 这种写法。所以如果设计师在大图上设计了一个 1px(真实像素)的线的话,前端工程师直接除以 2,写 0.5px(css) 就好了。
另外一种解释
事实就是它并没有变粗,就是 css 单位中的 1px,对于 dpr 为 2 的设备,它实际能显示的最小值是 0.5px。
设计师口中说的 1px 是针对设备物理像素的,换算成 css 像素就是 0.5px。
一句话总结,background:1px solid black 在任何屏幕上都是一样粗的,但是 retina 屏可以显示比这更细的边框,然后设计师就不乐意了,让你改。..
浏览器是如何渲染页面的?
答:
解析 HTML 文件,创建 DOM 树
自上而下,遇到任何样式(link、style)与脚本(script)都会阻塞(外部样式不阻塞后续外部脚本的加载)。
解析 CSS
优先级:浏览器默认设置<用户设置<外部样式<内联样式<HTML中的style样式;
构建渲染树
将 CSS 与 DOM 合并,构建渲染树(Render Tree)
布局和绘制
布局和绘制,重绘(repaint)和重排(reflow)
如何写出高性能的 HTML?
答:
避免使用 Iframe
Iframe 也叫内联 frame,可以把一个 HTML 文档嵌入到另一个文档中。使用 iframe 的好处是被嵌入的文档可以完全独立于其父文档,凭借此特点我们通常可以使浏览器模拟多线程,需要注意的是使用 iframe 并不会增加同域名下的并行下载数,浏览器对同域名的连接总是共享浏览器级别的连接池,即使是跨窗口或跨标签页,这在所有主流浏览器都是如此。也因为这样这让 iframe 带来的好处大打折扣。
在页面加载过程中 iframe 元素会阻塞父文档 onload 事件的触发,而开发者程序通常会在 onload 事件触发时初始化 UI 操作。例如,设置登录区域的焦点。因为用户习惯等待这一操作,所以尽可能的让 onload 事件触发从而使用户的等待时间变短是非常重要的。另外开发者会把一些重要的行为绑定在 unload 事件上,而不幸的是在一些浏览器中,只有当 onload 事件触发后 unload 事件才能触发,如果 onload 事件长时间未触发,而用户已经离开当前页面,那么 unload 事件也将永远得不到触发。 那是否有方案可以让 onload 事件不被 iframe 阻塞吗?有个简单的解决方案来避免 onload 事件被阻塞,使用 JavaScript 动态的加载 iframe 元素或动态设置 iframe 的 src 属性:
document.getElementById(‘iframe1’).setAttribute(‘src’, ‘url’);
但其仅在高级浏览器 中有效,对于 Internet Explorer 8 及以下的浏览器无效。除此之外我们必须知道 iframe 是文档内最消耗资源的元素之一,在 Steve Souders 的测试中 ,在测试页面中分别加载 100 个 A、DIV、SCRIPT、STYLE 和 IFRAME 元素,并且分别在 Chrome、Firefox、Internet Explorer、Opera、Safari 中运行了 10 次。结果显示创建 iframe 元素的开销比创建其他类型的 DOM 元素要高 1~2 个数量级。在测试中所有的 DOM 元素都是空的,如加载大的脚本或样式块可能比加载某些 iframe 元素耗时更长,但从基准测试结果来看,即使是空的 iframe,其开销也是非常昂贵的,鉴于 iframe 的高开销,我们应尽量避免使用。尤其是对于移动设备,对于目前大部分还是只有有限的 CPU 与内存的情况下,更应避免使用 iframe。
避免空链接属性
空的链接属性是指 img、link、script、ifrrame 元素的 src 或 href 属性被设置了,但是属性却为空。如<img src=''>,我们创建了一个图片,并且暂时设置图片的地址为空,希望在未来动态的去修改它。但是即使图片的地址为空,浏览器依旧会以默认的规则去请求空地址:
- Internet Explorer 8 及以下版本浏览器只在 img 类型元素上出现问题,IE 会把 img 的空地址解析为当前页面地址的目录地址。例如:如果当前页面地址为 会把空地址解析为 地址并请求。
- 早些版本的 Webkit 内核浏览器 与 Firefox 会把空地址解析为当前页面的地址。如果页面内有多个空链接属性元素,当前页面的服务器则会被请求多次,增加服务器的负载。相较桌面浏览器对内核的更新升级较积极,这个问题在 ios 与 android 系统的移动浏览器上问题可能较严重。
- 幸运的是所有主流浏览器面对 iframe 的 src 属性为空时,会把空地址解析为 about:blank 地址,而不会向服务器发出额外的请求。
避免节点深层级嵌套
深层级嵌套的节点在初始化构建时往往需要更多的内存占用,并且在遍历节点时也会更慢些,这与浏览器构建 DOM 文档的机制有关。例如下面 HTML 代码:
Hello World

通过浏览器 HTML 解析器的解析,浏览器会把整个 HTML 文档的结构存储为 DOM 树结构。当文档节点的嵌套层次越深,构建的 DOM 树层次也会越深。
缩减 HTML 文档大小
提高下载速度最显而易见的方式就是减少文件的大小,特别是压缩内嵌在 HTML 文档中的 JavaScript 和 CSS 代码,这能使得页面体积大幅精简。除此之外减少 HTML 文档大小还可以采取下面几种方法:
- 删掉 HTM 文档对执行结果无影响的空格空行和注释
- 避免 Table 布局
- 使用 HTML5
显式指定文档字符集
HTML 页面开始时指定字符集,有助于浏览器可以立即开始解析 HTML 代码。HTML 文档通常被解析为一序列的带字符集编码信息的字符串通过 internet 传送。字符集编码在 HTTP 响应头中,或者 HTML 标记中指定。浏览器根据获得的字符集,把编码解析为可以显示在屏幕上的字符。如果浏览器不能获知页面的编码字符集,一般都会在执行脚本和渲染页面前,把字节流缓存,然后再搜索可进行解析的字符集,或以默认的字符集来解析页面代码,这会导致消耗不必要的时间。为了避免浏览器把时间花费在搜寻合适的字符集来进行解码,所以最好在文档中总是显式的指定页面字符集。
显式设置图片的宽高
当浏览器加载页面的 HTML 代码时,有时候需要在图片下载完成前就对页面布局进行定位。
如果 HTML 里的图片没有指定尺寸(宽和高),或者代码描述的尺寸与实际图片的尺寸不符时,浏览器则要在图片下载完成后再 “回溯” 该图片并重新显示,这会消耗额外时间。
所以,最好为页面里的每一张图片都指定尺寸,不管是在页面 HTML 里的<img> 标签,还是在 CSS 里。

避免脚本阻塞加载
当浏览器在解析常规的 script 标签时,它需要等待 script 下载完毕,再解析执行,而后续的 HTML 代码只能等待。为了避免阻塞加载,应把脚步放到文档的末尾,如把 script 标签插入在 body 结束标签之前:
iframe 的优缺点?
答:
- iframe 会阻塞主页面的 Onload 事件;
- iframe 和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
- 使用 iframe 之前需要考虑这两个缺点。如果需要使用 iframe,最好是通过 javascript 动态给 iframe 添加 src 属性值,这样可以可以绕开以上两个问题。
Canvas 和 SVG 图形的区别是什么?
答:Canvas 和 SVG 都可以在浏览器上绘制图形。
SVG Canvas 绘制后记忆,换句话说任何使用 SVG 绘制的形状都能被记忆和操作,浏览器可以再次显示 Canvas 则是绘制后忘记,一旦绘制完成你就不能访问像素和操作它 SVG 对于创建图形例如 CAD 软件是良好的,一旦东西绘制,用户就想去操作它 Canvas 则用于绘制和遗忘类似动漫和游戏的场画。
为了之后的操作,SVG 需要记录坐标,所以比较缓慢。
因为没有记住以后事情的任务,所以 Canvas 更快。
我们可以用绘制对象的相关事件处理我们不能使用绘制对象的相关事件处理,因为我们没有他们的参考分辨率独立分辨率依赖
- SVG 并不属于 html5 专有内容,在 html5 之前就有 SVG。
- SVG 文件的扩展名是”.svg”。
- SVG 绘制的图像在图片质量不下降的情况下被放大。
- SVG 图像经常在网页中制作小图标和一些动态效果图。
聊聊 meta 标签?
答:核心
提供给页面的一些元信息(名称 / 值对),有助于 SEO。
属性值
name
名称 / 值对中的名称。author、description、keywords、generator、revised、others。 把 content 属性关联到一个名称。
http-equiv
没有 name 时,会采用这个属性的值。content-type、expires、refresh、set-cookie。把 content 属性关联到 http 头部
content
名称 / 值对中的值, 可以是任何有效的字符串。 始终要和 name 属性或 http-equiv 属性一起使用
scheme
用于指定要用来翻译属性值的方案。

CSS 面试题
CSS3有哪些新特性?
答:
- 新增各种CSS选择器 (: not(.input):所有 class 不是“input”的节点)
- 圆角 (border-radius:8px)
- 多列布局 (multi-column layout)
- 阴影和反射 (Shadow\Reflect)
- 文字特效 (text-shadow、)
- 文字渲染 (Text-decoration)
- 线性渐变 (gradient)
- 旋转 (transform)
- 增加了旋转,缩放,定位,倾斜,动画,多背景
- transform:scale(0.85,0.90) translate(0px,-30px) skew(-9deg,0deg) Animation:
清除浮动的⼏种⽅式,各⾃的优缺点?
答:
- ⽗级 div 定义 height
- 结尾处加空 div 标签 clear:both
- ⽗级 div 定义伪类 :after 和 zoom
- ⽗级 div 定义 overflow:hidden
- ⽗级 div 也浮动,需要定义宽度
- 结尾处加 br 标签 clear:both
- ⽐较好的是第3种⽅式,好多⽹站都这么⽤
请解释一下CSS3的Flexbox(弹性盒布局模型)?
答:设为Flex布局以后( display: flex;),子元素的float、clear和vertical-align属性将失效。
采用Flex布局的元素,称为Flex容器(flex container),简称”容器”。
它的所有子元素自动成为容器成员,称为Flex项目(flex item),简称”项目”。
容器默认存在两根轴:水平的主轴(main axis)和垂直的交叉轴(cross axis)。
主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;交叉轴的开始位置叫做cross start,结束位置叫做cross end。
项目默认沿主轴排列。单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
容器的属性
以下6个属性设置在容器上(justify-content和align-items、flex-wrap:wrap最常用的)。
- justify-content:定义了项目在主轴上的对齐方式。它可能取5个值
- center: 居中
- flex-start(默认值):左对齐
- flex-end:右对齐
- space-between:两端对齐,项目之间的间隔都相等。
- space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
- align-items:属性定义项目在交叉轴上如何对齐。它可能取5个值。
- center:交叉轴的中点对齐。
- flex-start:交叉轴的起点对齐。
- flex-end:交叉轴的终点对齐。
- baseline: 项目的第一行文字的基线对齐。
- stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。
- flex-flow:flex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap。
- flex-direction:属性决定主轴的方向(即项目的排列方向);
- row(默认值):主轴为水平方向,起点在左端。
- row-reverse:主轴为水平方向,起点在右端。
- column:主轴为垂直方向,起点在上沿。
- column-reverse:主轴为垂直方向,起点在下沿。
- flex-wrap:默认情况下,项目都排在一条线(又称”轴线”)上。flex-wrap属性定义,如果一条轴线排不下,如何换行。
- 它可能取三个值。
- (1)nowrap(默认):不换行。
- (2)wrap:换行,第一行在上方。【这个属性经常用】
- (3)wrap-reverse:换行,第一行在下方。
- align-content:属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用
- flex-start:与交叉轴的起点对齐。
- flex-end:与交叉轴的终点对齐。
- center:与交叉轴的中点对齐。
- space-between:与交叉轴两端对齐,轴线之间的间隔平均分布。
- space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔大一倍。
- stretch(默认值):轴线占满整个交叉轴。
项目的属性总结
以下6个属性设置在项目上。(align-self、flex、order)
- align-self:
- 属性允许单个项目有与其他项目不一样的对齐方式,可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch;该属性可能取6个值,除了auto,其他都与align-items属性完全一致。
- auto / flex-start / flex-end / center / baseline / stretch;
- flex:
- 属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。该属性有两个快捷值:auto (1 1 auto) 和 none (0 0 auto)。建议优先使用这个属性,而不是单独写三个分离的属性,因为浏览器会推算相关值。
- order:
- 属性定义项目的排列顺序。数值越小,排列越靠前,默认为0。
- flex-grow:
- 属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
- flex-shrink:
- flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。负值对该属性无效。
- flex-basis:
- flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。它可以设为跟width或height属性一样的值(比如350px),则项目将占据固定空间。
解释下浮动和它的工作原理?清除浮动的技巧?
答:浮动元素脱离文档流,不占据空间。
浮动元素碰到包含它的边框或者浮动元素的边框停留
使用空标签清除浮动
这种方法是在所有浮动标签后面添加一个空标签 定义css clear:both. 弊端就是增加了无意义标签。
使用overflow
给包含浮动元素的父标签添加css属性 overflow:auto; zoom:1; zoom:1用于兼容IE6。
引入样式表CSS的方式有几种?分别是什么?优先级是什么?
答:在HTML中常用以下四种方式定义CSS:
- inline(内联式,也称行内样式)、
- embedding(嵌入式)、
- linking(外部引用式)
- 导入样式表(@import )。
详细
- 一:内联式/行内样式:使用该属性可以直接指定样式,当然,该样式仅能用于该元素的内容,对于另一个同名的元素则不起作用。
- 二:嵌入式(style):用户可在HTML文档头部定义多个style元素,实现多个样式表。
-
三:外部引用式(link)
- ①可以在多个文档间共享样式表,对于较大规模的网站,将CSS样式定义独立成一个一个的文档,可有效地提高效率,并有利于对网站风格的维护。
- ②可以改变样式表,而无需更改HTML文档,这也与HTML语言内容与形式分开的原则相一致。
- ③可以根据介质有选择的加载样式表。
-
四:导入样式表:@import url(“css/base.css”);
优先级:就近原则
内联式>内嵌式>外部引用式>导入样式表
什么是响应式设计?响应式设计的基本原理是什么?
答:响应式设计简而言之,就是一个网站能够兼容多个终端——而不是为每个终端做一个特定的版本。
优点
- 面对不同分辨率设备灵活性强
- 能够快捷解决多设备显示适应问题
缺点
兼容各种设备工作量大,效率低下
代码累赘,会出现隐藏无用的元素,加载时间加长
其实这是一种折中性质的设计解决方案,多方面因素影响而达不到最佳效果
一定程度上改变了网站原有的布局结构,会出现用户混淆的情况
【通过这三个步骤,你一定可以了解响应式设计的基本原理和media query】
第一步. Meta 标签
为了适应屏幕,多数的移动浏览器会把HTML网页缩放到设备屏幕的宽度。你可以使用meta标签的viewport属性来设置。下面的代码告诉浏览器使用设备屏幕宽度作为内容的宽度,并且忽视初始的宽度设置。这段代码写在 <head>里面
IE8及以下的浏览器不支持media query。你可以使用 media-queries.js 或 respond.js 。这样IE就能支持media query了。
第二步. HTML 结构
这个例子里面,有header、content、sidebar和footer等基本的网页布局。
header 有固定的高180px,content 容器的宽是600px,sidebar的宽是300px。
第三步. Media Queries
CSS3 media query 响应式网页设计的关键。它像一个if语句,告诉浏览器如何根据特定的屏幕宽口来加载网页。
如果屏幕窗口小于980px,规则就生效。设置了容器的宽度为百分比的形式而不是像素单位,这样会更加灵活。
如果文档宽度小于 300 像素则修改背景演示(background-color):
@media screen and (max-width: 300px) { body { background-color:lightblue; }} 用纯CSS创建一个三角形的原理是什么?
答:均分原理
在矩形的直角,两条边的样式要均分
比如左上角 border-top 和 border-left 的样式要均分
如果border-left 无色透明, border-top有色, 就会出来一个45度的锐角
说说盒子模型?
答:很简单,但是能说好比较难度的,可以扩展,回答越深,越广,加分越多
内容+padding+border+margin这个说一遍,然后话风一转,说如果在移动端,这个盒子模型就不是很适合做开发了,最好用box-sizing: border-box;属性改变一下盒子模型;
写了这个属性之后宽度会包括border,因为移动端主要是用百分比,不可能通过像素精确控制,如果让两个屏幕50%的div并排,而且这两个div还有border和padding,原来的盒子模型就做不到,必用用这个css属性改变一下才可以的,但是还有一个问题;
用inline-block让两个div并排后,中间会一个空白字符,还要把换行代码写在一行,或者用font-size:0;来解决
两种盒子模型
css3中定义了box-sizing属性;在移动端的应用;
- padding和margin的简写写法
- margin的两种居中DIV方法;(margin:0 auto;和负margin的写法)
- margin的兼容性问题,IE6img下面有空白;
- border的CSS3新增属性;
- border写三角形的用法;
对BFC的规范的理解?
答:(W3C CSS 2.1 规范中的一个概念,它决定了元素如何对其内容进行定位,以及与其他元素的关 系和相互作用。)
BFC,块级格式化上下文,一个创建了新的BFC的盒子是独立布局的,盒子里面的子元素的样式不会影响到外面的元素
。在同一个 BFC 中的两个毗邻的块 级盒在垂直方向(和布局方向有关系)的 margin 会发生折叠。
一个页面是由很多个 Box 组成的,元素的类型和 display 属性,决定了这个 Box 的类型。
不同类型的 Box,会参与不同的 Formatting Context(决定如何渲染文档的容器),因此Box内的元素会以不同的方式渲染,也就是说BFC内部的元素和外部的元素不会互相影响。
为什么说position absolute 跟float 影响性能?
答:position: absolute会完全脱离文档流
不再在z-index:0层保留占位符,其left、top、right、bottom 值是相对于自己最近的一个位置设置了position: relative 或 position: absolute的祖先元素的;
如果祖先元素都没有设置position: relative 或 position: absolute,那么就相对于body元素。
float也能改变文档流
不同的是,float属性不会让元素“上浮”到另一个z-index层,它仍然让元素在z-index:0层排列,float不像position: relative 和 position: absolute那样,它不能通过left、top、right、bottom属性精确地控制元素的坐标,它只能通过float:left 和 float:right 来控制元素在同层里“左浮”和“右浮”。float会改变正常的文档流排列,影响到周围元素。
另一个有趣的现象是position: absolute 和 float会隐式地改变display类型,不论之前什么类型的元素(display:none除外),只要设置了position: absolute 或 float中任意一个,都会让元素以display:inline-block的方式显示:可以设置长宽,默认宽度并不占满父元素。
就算我们显示地设置display:inline或者display:block,也仍然无效(float在IE6 下的双倍边距bug就是利用添加display:inline来解决的)。
值得注意的是,position: relative却不改变display的类型。
position属性为absolute或fixed的元素,重排的开销会比较小,因为不用考虑它对其他元素的影响
这一条规则可以解释:为什么在移动开发时尽量使用Position:absolute;而不是float来浮动元素
JS为什么会放在下面,CSS为什么放在上面?
答:浏览器从上到下依次解析html文档。
将 css 文件放到头部, css 文件可以先加载。避免先加载 body 内容,导致页面一开始样式错乱,然后闪烁。
将 javascript 文件放到底部是因为:若
将 javascript 文件放到 head 里面,就意味着必须等到所有的 javascript 代码都被 下载、解析和执行完成 之后才开始呈现页面内容。
这样就会造成呈现页面时出现明显的延迟,窗口一片空白。
为避免这样的问题一般将全部 javascript 文件放到 body 元素中页面内容的后面。
浮动元素引起的问题和解决办法?
答:
- 父元素的高度无法被撑开,影响与父元素同级的元素
- 与浮动元素同级的非浮动元素会跟随其后
- 若非第一个元素浮动,则该元素之前的元素也需要浮动,否则会影响页面显示的结构
额外标签法
缺点:不过这个办法会增加额外的标签使HTML结构看起来不够简洁。
使用after伪元素
#parent:after{ content : "."; height : 0; visibility : hidden; display : block; clear : both;} 父元素也设置浮动
缺点:使得与父元素相邻的元素的布局会受到影响,不可能一直浮动到body,不推荐使用
CSS的浏览器兼容性问题总结:
答:所谓的浏览器兼容性问题,是指因为不同的浏览器对同一段代码有不同的解析,造成页面显示效果不统一的情况。
在大多数情况下,我们的需求是,无论用户用什么浏览器来查看我们的网站或者登陆我们的系统,都应该是统一的显示效果。
除了IE6和7的自身bug,其他浏览器BUG很少的。如果你理解了每一句CSS的意思,规范编写代码,一般很少会出bug。
举个很简单的例子,很多人float:left后,担心IE6的双margin bug,不管三七二十一,加display:inline。其实这是错的。你要搞清楚IE6的双margin bug是如何产生的:
浮动方向有同方向的margin值,才会出现这个bug。所以如果只是单纯浮动,是不会产生这个bug的。
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
解决方案:CSS里 *{margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设置各个标签的内外补丁是0。
浏览器兼容问题二:块属性标签float后,又有横行的margin情况下,在IE6显示margin比设置的大
问题症状:常见症状是IE6中后面的一块被顶到下一行
碰到频率:90%(稍微复杂点的页面都会碰到,float布局最常见的浏览器兼容问题)
解决方案:在float的标签样式控制中加入 display:inline;将其转化为行内属性
备注:我们最常用的就是div+CSS布局了,而div就是一个典型的块属性标签,横向布局的时候我们通常都是用div float实现的,横向的间距设置如果用margin实现,这就是一个必然会碰到的兼容性问题。
浏览器兼容问题三:设置较小高度标签(一般小于10px),在IE6,IE7,遨游中高度超出自己设置高度
问题症状:IE6、7和遨游里这个标签的高度不受控制,超出自己设置的高度
碰到频率:60%
解决方案:给超出高度的标签设置overflow:hidden;或者设置行高line-height 小于你设置的高度。
备注:这种情况一般出现在我们设置小圆角背景的标签里。出现这个问题的原因是IE8之前的浏览器都会给标签一个最小默认的行高的高度。
即使你的标签是空的,这个标签的高度还是会达到默认的行高。
浏览器兼容问题四:行内属性标签,设置display:block后采用float布局,又有横行的margin的情况,IE6间距bug
问题症状:IE6里的间距比超过设置的间距
碰到几率:20%
解决方案:在display:block;后面加入display:inline;display:table;
备注:行内属性标签,为了设置宽高,我们需要设置display:block;(除了input标签比较特殊)。
在用float布局并有横向的margin后,在IE6下,他就具有了块属性float后的横向margin的bug。
不过因为它本身就是行内属性标签,所以我们再加上display:inline的话,它的高宽就不可设了。这时候我们还需要在display:inline后面加入display:talbe。
浏览器兼容问题五:图片默认有间距
问题症状:几个img标签放在一起的时候,有些浏览器会有默认的间距,加了问题一中提到的通配符也不起作用。
碰到几率:20%
解决方案:使用float属性为img布局
备注:因为img标签是行内属性标签,所以只要不超出容器宽度,img标签都会排在一行里,但是部分浏览器的img标签之间会有个间距。
去掉这个间距使用float是正道。(我的一个学生使用负margin,虽然能解决,但负margin本身就是容易引起浏览器兼容问题的用法,所以我禁止他们使用)
浏览器兼容问题六:标签最低高度设置min-height不兼容
问题症状:因为min-height本身就是一个不兼容的CSS属性,所以设置min-height时不能很好的被各个浏览器兼容
碰到几率:5%
解决方案:如果我们要设置一个标签的最小高度200px,需要进行的设置为:{min-height:200px; height:auto !important; height:200px; overflow:visible;}
备注:在B/S系统前端开时,有很多情况下我们又这种需求。当内容小于一个值(如300px)时。
容器的高度为300px;当内容高度大于这个值时,容器高度被撑高,而不是出现滚动条。这时候我们就会面临这个兼容性问题。
浏览器兼容问题七:透明度的兼容CSS设置
做兼容页面的方法是:每写一小段代码(布局中的一行或者一块)我们都要在不同的浏览器中看是否兼容,当然熟练到一定的程度就没这么麻烦了。
建议经常会碰到兼容性问题的新手使用。很多兼容性问题都是因为浏览器对标签的默认属性解析不同造成的,只要我们稍加设置都能轻松地解决这些兼容问题。
如果我们熟悉标签的默认属性的话,就能很好的理解为什么会出现兼容问题以及怎么去解决这些兼容问题。
/* CSS hack*/ 我很少使用hacker的,可能是个人习惯吧,我不喜欢写的代码IE不兼容,然后用hack来解决。
不过hacker还是非常好用的。使用hacker我可以把浏览器分为3类:IE6 ;IE7和遨游;其他(IE8 chrome ff safari opera等)
IE6认识的hacker 是下划线_ 和星号 *
IE7 遨游认识的hacker是星号 *
比如这样一个CSS设置:
height:300px;*height:200px;_height:100px; IE6浏览器在读到height:300px的时候会认为高时300px;
继续往下读,他也认识*heihgt, 所以当IE6读到*height:200px的时候会覆盖掉前一条的相冲突设置,认为高度是200px。
继续往下读,IE6还认识_height,所以他又会覆盖掉200px高的设置,把高度设置为100px;
IE7和遨游也是一样的从高度300px的设置往下读。
当它们读到*height200px的时候就停下了,因为它们不认识_height。所以它们会把高度解析为200px,剩下的浏览器只认识第一个height:300px;所以他们会把高度解析为300px。
因为优先级相同且想冲突的属性设置后一个会覆盖掉前一个,所以书写的次序是很重要的。
怎么让Chrome支持小于12px 的文字?
答:
html, body {-webkit-text-size-adjust: none;} 新版的chrome已经取消了;
CSS3有个新的属性transform,而我们用到的就是transform:scale()
p{font-size:10px;-webkit-transform:scale(0.8);} 但是,如果,这个属性会把整个p的属性都缩放。如果我有背景呢?我有边框呢?都会被缩小!
所以我们修改结构为
我是一个小于12PX的字体
代码如下
body,p{ margin:0; padding:0}p{font-size:10px;}span{-webkit-transform:scale(0.8); display:inline-block} 定义 display:inline-block而不是 display:block;会发现。
会存在一定的边距。貌似margin或者padding的间距。
这就是缩放存在问题。原来的位置还占有12px字体的大小。
所以,要对应修改margin了。定义为负的。
还有一个网上别人分享的方法;
html {font-size: 625%;}body {font-size: 0.16rem;}

JavaScript 面试题
JavaScript 中有几种数据类型?
答:数据类型可以分为基本数据类型和引用数据类型
基本数据类型 :String、Number、Boolean 、Null、Undefined、Symbol、BigInt ;
引用数据类型:Object;
有些小伙伴喜欢把引用数据类型这块分为 Object 和 Funtion,这也是可以的,(主要是 typeof可以检测function,还有就是Function这个类比较特殊)
其中 Symbol、BigInt 是新增的数据类型
JavaScript []和{}表示什么?
答:[]表示数组,
{}表示对象,
这2种声明方式都为字面量方式。
除了字面量方式外还可以用new Array及new Object来实例化。
JavaScript 什么叫全局变量?什么叫局部变量了?是如何定义出来的?
答:全局变量是在函数外部定义的变量,在JS中全局变量属于window对象,其作用域是整个源程序,全局变量全部存放在静态存储区,在程序开始执行时给全局变量分配存储区,程序运行完毕就释放。
局部变量是相对与全局变量而言的,在特定过程或函数中可以访问的变量,作用域较小,当函数运行结束释放局部变量。
在JavaScript中并没有明确局部变量的概念,是相对于其他编程语言来描述。
参考《JavaScript高级程序设计》中,变量分全局变量和函数变量。
什么叫保留字?在定义变量时我们应该注意哪些?
保留字是JavaScript中已经定义过的字,由于考虑扩展性,一些保留字可能并没有应用于当前的语法中,这是保留字与关键字的区别。
如class、abstract是保留字。在定义变量时应避免与保留字取名相同;
说一说html代码,css代码和js代码的注释方法?
答:HTML注释语法
css注释语法
/* 注释内容 */
javaScript注释
//注释内容/*注释内容*/
写一个从0到59依次循环的计时器?
答:
var flag = 0;function timer () { flag++; if (flag > 59) { flag = 0; return; } console.log(flag);}setInterval(timer, 1000); JavaScript 事件冒泡机制?
答:事件传播机制(不管是DOM0还是DOM2,这个机制是天生就带的);
当触发底层元素的某一个事件行为,那么它的上级元素的对应事件行为也会一级级的触发,一直出发到我们的document;(只有相同的事件类型才会触发)
从底层一级级往上传播的机制叫做冒泡;
DOM2级绑定事件,第三个参数写false代表的是冒泡阶段执行,如果写的是true,代表的是在捕获阶段执行;
同一个元素既可以在捕获阶段处理也可以在冒泡阶段处理;
DOM0级基本上只能控制冒泡阶段,而DOM2级是可以控制捕获阶段的;
事件委托
利用DOM的传播机制(点击任意元素,document的click都要出发),我们给document绑定一个点击事件,在事件中我们只需要获取事件源;根据不同的事件源做不同的事件就可以的了(这样就可以不用给元素一个个的绑定事件的了);
当事件发生在子元素中的时候,旺旺会引起连锁反应,就是在它的祖先元素上也会发生这个事件,比如说你点击了div一个,也相当于点击了一个body,同样相当于点击了html,同样相当于点击了document;
理解事件传播的时候要注意两点;
一是事件本身在传播,而不是绑定在事件上的方法会传播;
二是并非所有的事件都会传播,像onfocus,onblur事件就不传播,onmouseenter和onmouseleave事件也不会传播;
我们要知道常见的事件默认行为有哪些,并且要知道组织默认行为,只要绑定到这个行为事件的方法最后加一句,return false就可以了;
但是需要强调的是,如果你的事件绑定是用addEventListener来实现的,那么组织默认行为必须用e.preventDefault=true;
阻止事件冒泡
function (e) {e.preventDefault();} 事件委托:事件委托就是用事件的传播机制,无论哪一个网页元素,它的click事件都会最终传到document上,这样,则只需在document上处理click事件即可;
document.onclick=function(e){e=e||window.event;var target=e.targrt||e.srcElement;//获取事件源是关键;alert(target.nodeName);return false;} 事件委托的关键是理解好事件源的概念;
JavaScript 事件兼容性问题有哪些?怎么解决?
答:1、事件对象本身,标准浏览器是时间发生时自动给方法传一个实参,这个实参就是时间对象,IE是全局的window.event;(解决方法是:e=e||window.event)
2、事件源:e.target,IE下是e.srcElement;(解决办法是是 var target=e.target||e.srcElement;)
3、DOM二级事件绑定:ele.addEventListener,IE是ele.attachEvent;
解决办法是通过
if(ele.addEventListener){}else if(ele.attachEvent){} 这样的方法来解决绑定对应的移除方法是removeEventListener和IE的detachEvent;
4、第三点中的IE的attachEvent绑定的方法上,
- 第一点、this不是当前元素了,而是变成了window;
- 第二点,事件的执行顺序是混乱的;
- 在IE678中,如果绑定的方法少于9个,执行的顺序是相反的,如果多于9个,执行的是混乱的;
- 第三点,同一函数可以重复绑定在同一事件上;
- 需要解决一个函数不能重复绑定在同一个事件上,低版本IE没有遵循这个原则;要保证一个方法只能被绑定到某事件上一次;
5、阻止事件传播;e.stopPropagation,IE是e.cancelBubble=true这个属性;这个一般不做处理,用这个属性,还可以做观察者模式的;
6、阻止默认行为:e.preventDefault()方法,IE是e.returnValue=false;
7、e.pageX,e.pageY;相对于文档的鼠标坐标IE不支持这两个属性;但都支持clentX,clentY,这个是相对于浏览器的鼠标坐标。可以通过scrollTop+clientY来实现; Î
e.pageX=(document.documentElement.scrollLeft||document.body.scrollLeft)+ e.clientX;e.pageY=(document.documentElement.scrollTop||document.body.scrollTop)+ e.clientY;
JavaScript DOM创建元素,添加元素,移动元素,复制节点,删除,替换元素,查找节点的方法?
答:创建元素
document.createElement('tagName'); 添加元素
parent.appendChild(childNode);
注:父元素调用该方法
移动元素
由于DOM对象属于引用类型,所以在操作appendChild和insertBefore方法时,
控制的节点如果是文档中存在的节点,那么将把这个节点移到目标处。
复制节点
oLi.cloneNode(true);
注:参数true表示深度克隆(深拷贝),false 表示浅度克隆(浅拷贝),深拷贝也就是复制节点及整个节点数;浅拷贝复制节点本身。复制后返回的节点副本属于文档所有,但并没有为它指定父节点。因此,整个节点副本就成为一个‘孤儿’:
- item 1
- item 2
- item 3
以上代码注意childNode包含文本节点。
cloneNode()方法不会复制添加DOM节点的JS属性,例如事件处理程序等。这个方法只复制特性,其他一切都不会复制。
删除节点
parentNode.removeChild(childNode);
注:父元素调用该方法,返回值为被删除的节点
替换元素
parentNode.replaceChild(newNode,oldNode);
注:oldNode节点必须是parentNode的子节点。
插入元素
parentNode.insertBefore(newEle, oldNode);
注:父元素调用该方法
查找节点的总结
- childNodes—返回节点到子节点的节点列表
- firstChild—返回节点的首个子节点;
- lastChild—返回节点的最后一个子节点;
- nextSibling—返回节点之后紧跟的同级节点;
- nodeName—返回节点的名字,根据其类型;
- nodeType—返回节点的类型;
- nodeValue—设置或返回节点的值,根据其类型;
- ownerDocument—返回节点的根元素(document对象);
- parentNode—返回节点的父节点;
- previousSibling—返回节点之前紧跟的同级节点;
- text—返回节点及其后代的文本(IE独有);
- xml—返回节点及其后代的XML(IE独有);
节点对象的方法
- appendChild()—向节点的子节点列表的结尾添加新的子节点;
- cloneNode()—复制节点;
- hasChildNodes()—判断当前节点是否拥有子节点;
- insertBefore()—在指定的子节点前插入新的子节点;
- normalize()—合并相邻的Text节点并删除空的Text节点;
- removeChild()—删除(并返回)当前节点的指定子节点;
- replaceChild()—用新节点替换一个子节点;
IE6独有方法
- selectNodes()—用一个XPath表达式查询选择节点;
- selectSingleNode()—查找和XPath查询匹配的一个节点;
- transformNode()—使用XSLT把一个节点转换为一个字符串。transformNodeToObject()—使用XSLT把一个节点转换成为一个文档。
经典的问题解析
创建新节点
- createDocumentFragment() //创建一个DOM片段
- createElement() //创建一个具体的元素
- createTextNode() //创建一个文本节点
添加、移除、替换、插入
- appendChild()
- removeChild()
- replaceChild()
- insertBefore() //在已有的子节点前插入一个新的子节点
查找
- getElementsByTagName() //通过标签名称
- getElementsByName() //通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的)
- getElementById() //通过元素Id,唯一性
您的DOM怎么封装的?各种库是怎么写的?(DOM库,AJAX库,动画库,事件库)?
答:在作用域套作用域的时候;子作用域内尽量不返回引用数据类型,因为闭包内的值,是另外一个子闭包的返回值的时候,如果子闭包的返回值是字面量,那么浏览器会在空闲的时候,把作用域销毁;而如果返回值的是一个引用数据类型的值,那么闭包是不会销毁的,在性能优化上,不好!
下面是封装思路;
var Tool = function () {//构造函数模式;用的时候需要new一下; this.flag = "getElementsByClassName" in document; //getElementsByClassName 在IE678中是不存在的。用这个来判断是不是低版本的IE浏览器; //每次只需要判断this.flag是否存在就可以了;如果存在就是标准浏览器,如果不存在就是IE;};Tool.prototype = {//方法是定义在Tool的prototype上的; constructor: Tool,//重写prototype后,prototype的constructor已经不是原来的Tool了;需要手动给他强制写会到Tool上去; getIndex: function () {},//简单的备注说明; toJSON:function(){},//简单的备注说明; likeArray:function(){}//简单的备注说明;} JavaScript 字符串的常用方法?
答:
- charAt 获取指定索引位置的字符
- charCodeAt 获取指定索引位置的字符对应的ASCII码值
- indeof/lasrIndexof 获取某个字符串在第一次(最后一次)出现位置的索引,没有的话返回-1,我们通常用这个来检测字符串中是否包含某一个字符;
- toUpperCase/tolowerCase将字符串中的字母转大写|小写;
- split按照指定的分隔符,讲一个字符串拆分成数组,和数组的join对应;
- substr:substr(n,m)从索引n开始截取m个字符,把截取字符返回一个新的字符串;
- substring:substring(n,m)从索引n开始截取到索引m处(不包含m),将找到的字符返回成一个新的字符串;
- slice:slice(n,m)和substring的用法和意思一样,只是slice可以支持负数作为索引,出现负数索引的时候,用字符串的长度+负数索引,例如:ary.slice(-6,-2),其实是ary.slice(ary.length-6,ary.length-2)
- 上面三个方法,如果只写一个n,都是默认截取到字符串末尾的位置;
- Replace:replace(“要替换的老字符”,“替换成的新字符”)字符串中字符替换的方法,可以应用正则来统一的进行替换,在正则中我们会详细的讲解replace的强大应用;
- Match:把所有和正则匹配到的内容都进行捕获(不能捕获小分组中的内容)
- trim: 去掉字符串中末尾位置的空白字符(不兼容)
JavaScript 正则验证,当下面的这个表单提交的时候,输入框中不能为空,如果有空格必须把空格去掉,必须是合法的手机号?
答:
var form1 = document.getElementById('form1');form1.onsubmit = function () { var mobi = document.getElementById('mobi'); var reg = /^1\d{10}$/; if (reg.test(mobi.value.replace(/ /g, ''))) { console.log('ok'); } else { console.log('error'); return false; }} 解释一下JavaScript的同源策略?
答:概念:同源策略是客户端脚本(尤其是Javascript)的重要的安全度量标准。
它最早出自Netscape Navigator2.0,其目的是防止某个文档或脚本从多个不同源装载。
这里的同源策略指的是:协议,域名,端口相同,
同源策略是一种安全协议:指一段脚本只能读取来自同一来源的窗口和文档的属性。
简述 JavaScript AJAX 的原理?
答:ajax是很多种技术的集合体。其中包括
浏览器的xmlHTTPRequest对象,他是负责为你开通另一条连接通道,可以传递信息。
javascript:他是负责调用XMLHTTPRequest对象进行与后台交互的媒介。
xml是一种数据格式,用于服务器应答传递信息的格式。除了xml外,还可以使用任何的文本格式,包括text,html,json等。
ajax并非一种新的技术,而是几种原有技术的结合体。它由下列技术组合而成。
-
使用CSS和XHTML来表示。
-
使用DOM模型来交互和动态显示。
-
使用XMLHttpRequest来和服务器进行异步通信。
-
使用javascript来绑定和调用。
在上面几中技术中,除了XmlHttpRequest对象以外,其它所有的技术都是基于web标准并且已经得到了广泛使用的,XMLHttpRequest虽然目前还没有被W3C所采纳,但是它已经是一个事实的标准,因为目前几乎所有的主流浏览器都支持它。
XMLHttpRequest是ajax的核心机制,它是在IE5中首先引入的,是一种支持异步请求的技术。简单的说,也就是javascript可以及时向服务器提出请求和处理响应,而不阻塞用户。达到无刷新的效果。
所以我们先从XMLHttpRequest讲起,来看看它的工作原理。
XMLHttpRequest 的属性
它的属性有:
- onreadystatechange 每次状态改变所触发事件的事件处理程序。
- responseText 从服务器进程返回数据的字符串形式。
- responseXML 从服务器进程返回的DOM兼容的文档数据对象。
- status 从服务器返回的数字代码,比如常见的404(未找到)和200(已就绪)
- status Text 伴随状态码的字符串信息
- readyState 对象状态值
0(未初始化) 对象已建立,但是尚未初始化(尚未调用open方法)1(初始化) 对象已建立,尚未调用send方法2(发送数据) send方法已调用,但是当前的状态及http头未知3(数据传送中) 已接收部分数据,因为响应及http头不全,这时通过responseBody和responseText获取部分数据会出现错误,4(完成) 数据接收完毕,此时可以通过通过responseXml和responseText获取完整的回应数据
但是,由于各浏览器之间存在差异,所以创建一个XMLHttpRequest对象可能需要不同的方法。
这个差异主要体现在IE和其它浏览器之间。下面是一个比较标准的创建XMLHttpRequest对象的方法。
function CreateXmlHttp () {//非IE浏览器创建XmlHttpRequest对象if (window.XmlHttpRequest) {xmlhttp = new XmlHttpRequest();}//IE浏览器创建XmlHttpRequest对象if (window.ActiveXObject) {try {xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");}catch (e) {try {xmlhttp = new ActiveXObject("msxml2.XMLHTTP");}catch (ex) { }}}}function Ustbwuyi () {var data = document.getElementById("username").value;CreateXmlHttp();if (!xmlhttp) {alert("创建xmlhttp对象异常!");return false;}xmlhttp.open("POST", url, false);xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState == 4) {document.getElementById("user1").innerHTML = "数据正在加载...";if (xmlhttp.status == 200) {document.write(xmlhttp.responseText);}}}xmlhttp.send();} 如上所示,函数首先检查XMLHttpRequest的整体状态并且保证它已经完成(readyStatus=4),即数据已经发送完毕。
然后根据服务器的设定询问请求状态,如果一切已经就绪(status=200),那么就执行下面需要的操作。
对于XmlHttpRequest的两个方法,open和send,其中open方法指定了:
-
a、向服务器提交数据的类型,即post还是get。
-
b、请求的url地址和传递的参数。
-
c、传输方式,false为同步,true为异步。默认为true。如果是异步通信方式(true),客户机就不等待服务器的响应;如果是同步方式(false),客户机就要等到服务器返回消息后才去执行其他操作。我们需要根据实际需要来指定同步方式,在某些页面中,可能会发出多个请求,甚至是有组织有计划有队形大规模的高强度的request,而后一个是会覆盖前一个的,这个时候当然要指定同步方式。
Send方法用来发送请求
知道了XMLHttpRequest的工作流程,我们可以看出,XMLHttpRequest是完全用来向服务器发出一个请求的,它的作用也局限于此,但它的作用是整个ajax实现的关键,因为ajax无非是两个过程,发出请求和响应请求。
并且它完全是一种客户端的技术。而XMLHttpRequest正是处理了服务器端和客户端通信的问题所以才会如此的重要。
现在,我们对ajax的原理大概可以有一个了解了。我们可以把服务器端看成一个数据接口,它返回的是一个纯文本流,当然,这个文本流可以是XML格式,可以是Html,可以是Javascript代码,也可以只是一个字符串。
这时候,XMLHttpRequest向服务器端请求这个页面,服务器端将文本的结果写入页面,这和普通的web开发流程是一样的,不同的是,客户端在异步获取这个结果后,不是直接显示在页面,而是先由javascript来处理,然后再显示在页面。至于现在流行的很多ajax控件,比如magicajax等,可以返回DataSet等其它数据类型,只是将这个过程封装了的结果,本质上他们并没有什么太大的区别。
HTTP状态码有哪些?分别代表什么意思?
答:
- 100-199 用于指定客户端应相应的某些动作。
- 200-299 用于表示请求成功。
- 300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
- 400-499 用于指出客户端的错误。400 1、语义有误,当前请求无法被服务器理解。401 当前请求需要用户验证 403 服务器已经理解请求,但是拒绝执行它。
- 500-599 用于支持服务器错误。 503 – 服务不可用;
常用的
- 100 Continue 继续,一般在发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
- 200 OK 正常返回信息
- 201 Created 请求成功并且服务器创建了新的资源
- 202 Accepted 服务器已接受请求,但尚未处理
- 301 Moved Permanently 请求的网页已永久移动到新位置。
- 302 Found 临时性重定向。
- 303 See Other 临时性重定向,且总是使用 GET 请求新的 URI。
- 304 Not Modified 自从上次请求后,请求的网页未修改过。
- 400 Bad Request 服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。
- 401 Unauthorized 请求未授权。
- 403 Forbidden 禁止访问。
- 404 Not Found 找不到如何与 URI 相匹配的资源。
- 500 Internal Server Error 最常见的服务器端错误。
- 503 Service Unavailable 服务器端暂时无法处理请求(可能是过载或维护)。
一个页面输入URL到页面加载显示完成,中间发生了什么?
答:
- 在浏览器地址栏输⼊URL
-
浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤
- 如果资源未缓存,发起新请求
- 如果已缓存,检验是否⾜够新鲜,⾜够新鲜直接提供给客户端,否则与服务器进⾏验 证。
- 检验新鲜通常有两个HTTP头进⾏控制 Expires 和 Cache-Control :
- HTTP1.0提供Expires,值为⼀个绝对时间表示缓存新鲜⽇期
- HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最⼤新鲜时间
-
浏览器解析URL获取协议,主机,端⼝,path
-
浏览器组装⼀个HTTP(GET)请求报⽂
-
浏览器获取主机ip地址,过程如下:
- 浏览器缓存
- 本机缓存
- hosts⽂件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不⼀样)
-
打开⼀个socket与⽬标IP地址,端⼝建⽴TCP链接,三次握⼿如下:
- 客户端发送⼀个TCP的SYN=1,Seq=X的包到服务器端⼝
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
-
TCP链接建⽴后发送HTTP请求
-
服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使⽤HTTP Host头部判断请 求的服务程序
-
服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码
-
处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
-
服务器将响应报⽂通过TCP连接发送回浏览器
-
浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重⽤,关闭TCP连接的四 次握⼿如下:
- 主动⽅发送Fin=1, Ack=Z, Seq= X报⽂
- 被动⽅发送ACK=X+1, Seq=Z报⽂
- 被动⽅发送Fin=1, ACK=X, Seq=Y报⽂
- 主动⽅发送ACK=Y, Seq=X报⽂
-
浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
-
如果资源可缓存,进⾏缓存
-
对响应进⾏解码(例如gzip压缩)
-
根据资源类型决定如何处理(假设资源为HTML⽂档)
-
解析HTML⽂档,构件DOM树,下载资源,构造CSSOM树,执⾏js脚本,这些操作没有严 格的先后顺序,以下分别解释
-
构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
-
解析过程中遇到图⽚、样式表、js⽂件,启动下载
-
构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
-
根据DOM树和CSSOM树构建渲染树 :
- 从DOM树的根节点遍历所有可⻅节点,不可⻅节点包括:1) script , meta 这样本身 不可⻅的标签。2)被css隐藏的节点,如 display: none
- 对每⼀个可⻅节点,找到恰当的CSSOM规则并应⽤
- 发布可视节点的内容和计算样式
-
js解析如下:
- 浏览器创建Document对象并解析HTML,将解析到的元素和⽂本节点添加到⽂档中,此 时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到⽂档中,然后执⾏⾏内 或外部脚本。这些脚本会同步执⾏,并且在脚本下载和执⾏时解析器会暂停。这样就可 以⽤document.write()把⽂本插⼊到输⼊流中。同步脚本经常简单定义函数和注册事件 处理程序,他们可以遍历和操作script和他们之前的⽂档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析⽂档。脚本会在它 下载完成后尽快执⾏,但是解析器不会停下来等它下载。异步脚本禁⽌使⽤ document.write(),它们可以访问⾃⼰script和之前的⽂档元素
- 当⽂档完成解析,document.readState变成interactive
- 所有defer脚本会按照在⽂档出现的顺序执⾏,延迟脚本能访问完整⽂档树,禁⽌使⽤ document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时⽂档完全解析完成,浏览器可能还在等待如图⽚等内容加载,等这些内容完成载⼊ 并且所有异步脚本完成载⼊和执⾏,document.readState变为complete,window触发 load事件
-
显示⻚⾯(HTML解析过程中会逐步显示⻚⾯)
异步加载和延迟加载?
答:
- 异步加载的方案: 动态插入script标签
- 通过ajax去获取js代码,然后通过eval执行
- script标签上添加defer或者async属性
- 创建并插入iframe,让它异步执行js
- 延迟加载:有些 js 代码并不是页面初始化的时候就立刻需要的,而稍后的某些情况才需要的。
对网站重构的理解?怎么重构页面?
答:怎么重构页面?
编写 CSS、让页面结构更合理化,提升用户体验,实现良好的页面效果和提升性能。
对网站重构的理解
网站重构:在不改变外部行为的前提下,简化结构、添加可读性,而在网站前端保持一致的行为。也就是说是在不改变UI的情况下,对网站进行优化,在扩展的同时保持一致的UI。
对于传统的网站来说重构通常是
-
表格(table)布局改为DIV+CSS
-
使网站前端兼容于现代浏览器(针对于不合规范的CSS、如对IE6有效的)
-
对于移动平台的优化
-
针对于SEO进行优化
-
深层次的网站重构应该考虑的方面
-
减少代码间的耦合
-
让代码保持弹性
-
严格按规范编写代码
-
设计可扩展的API
-
代替旧有的框架、语言(如VB)
-
增强用户体验
-
通常来说对于速度的优化也包含在重构中
-
压缩JS、CSS、image等前端资源(通常是由服务器来解决)
-
程序的性能优化(如数据读写)
-
采用CDN来加速资源加载
-
对于JS DOM的优化
-
HTTP服务器的文件缓存
JavaScript new操作符具体干了什么呢?
答:
- 创建一个空对象,并且 this 变量引用该对象,同时还继承了该函数的原型
- 属性和方法被加入到 this 引用的对象中
-
新创建的对象由 this 所引用,并且最后隐式的返回 this
var obj = {};obj.__proto__ = Base.prototype;Base.call(obj); JavaScript call和apply()的作用和区别?
答:核心
动态改变某个类的某个方法的运行环境,就是改变 this 关键字
- call是参数一个一个的传
- apply是把参数当做一个数据统一传进去,类似arguments;
call和apply的区别
-
Function.prototype.call 和 Function.prototype.apply 它们的作用一样,区别仅在于传入参数的形式的不同。
-
当使用 call 或者 apply 的时候,如果我们传入的第一个参数为 null,函数体内的 this 会指 向默认的宿主对象,在浏览器中则是 window
-
有时候我们使用 call 或者 apply 的目的不在于指 定this 指向,而是另有用途,比如借用其他对象的方法。那么我们可以传入 null 来代替某个具体的对象
call和apply的用途
- 改变this指向
- Function.prototype.bind
- 借用其他对象的方法
call
function add (a, b) {console.log(a + b);}function sub (a, b) {console.log(a - b);}add.call(sub, 3, 1);//用 add 来替换 sub,add.call(sub,3,1) == add(3,1) ,所以运行结果为: (4); js 中的函数其实是对象,函数名是对 Function 对象的引用
JavaScript 谈谈 this 对象的理解?
答:
this指的是调用函数的那个对象this在没有运行之前不能知道代表谁;js的this指向是不确定的;和定义没有关系,和执行有关,- 执行的时候,点前面是谁,
this就是谁;自执行函数里面的this代表的是window - 定时器书写的时候,window可以省略掉;定时器执行的时候,里面的
this代表的也是window; this是js的一个关键字,随着函数使用场合不同,this的值会发生变化。
JavaScript 什么是window对象? 什么是document对象?说说你的理解
答:
- document 是 window 的一个对象属性。
- window 对象表示浏览器中打开的窗口。
- 如果文档包含框架(frame 或 iframe 标签),浏览器会为 HTML 文档创建一个 window 对象,并为每个框架创建一个额外的 window 对象。
- 所有的全局函数和对象都属于Window 对象的属性和方法。
- 例如,可以只写 document,而不必写 window.document。
- 同样,可以把当前窗口对象的方法当作函数来使用,如只写 alert(),而不必写 Window.alert()。
- document 对 Document 对象的只读引用。
Javascript创建对象的几种方式?
答:
- 工厂模式
- 构造函数模式
- 原型模式
- 混合构造函数和原型模式
- 动态原型模式
- 寄生构造函数模式
- 稳妥构造函数模式
javascript创建对象简单的说,无非就是使用内置对象或各种自定义对象. 当然还可以用JSON;但写法有很多种. 也能混合使用。
1、对象字面量的方式
person={firstname:"zhu",lastname:"anbang",age:25,eyecolor:"black"}; 2、用function来模拟无参的构造函数
function Person(){}var person=new Person();//定义一个function. 如果使用new"实例化",该function可以看作是一个Classperson.name="zhu";person.age="25";person.work=function(){alert(person.name+" hello...");}person.work(); 3、用function来模拟参构造函数来实现(用this关键字定义构造的上下文属性)
function Pet(name,age,hobby){this.name=name;//this作用域:当前对象this.age=age;this.hobby=hobby;this.eat=function(){alert("我叫"+this.name+",我喜欢"+this.hobby+",是个程序员");}}var maidou =new Pet("麦兜",25,"coding");//实例化、创建对象maidou.eat();//调用eat方法 4、用工厂方式来创建(内置对象)
var wcDog =new Object();wcDog.name="旺财";wcDog.age=3;wcDog.work=function(){alert("我是"+wcDog.name+",汪汪汪......");}wcDog.work(); 5、用原型方式来创建
function Dog(){}Dog.prototype.name="旺财";Dog.prototype.eat=function(){alert(this.name+"是个吃货");}var wangcai =new Dog();wangcai.eat(); 5、用混合方式来创建
function Car(name,price){this.name=name;this.price=price;}Car.prototype.sell=function(){alert("我是"+this.name+". 我现在卖"+this.price+"万元");}var camry =new Car("凯美瑞",27);camry.sell(); JavaScript 模块化开发怎么做?
答:核心:立即执行函数,不暴露私有成员
var module1 = (function () {var _count = 0;var m1 = function () {//...};var m2 = function () {//..};return {m1: m1,m2: m2};})(); 求数组中的最大值 var ary=[1,2,3,5,7,90,3,6];
答:alert(Math.max.apply(null,a))。
知识点:将a作为参数传递,返回值为排序后的新数组,第一个参数为null因为不需要借用对象,此值可以忽略。
var a = [3, 4, 6, 2, 9, 11, 4];var maxNum = Math.max.apply(null, a);console.log(maxNum);//11
注意:a被当做参数传递进去,因为调用对象可以忽略,所以第一个参数为null,
Math.max.apply返回的是一个新值。
还有一种方法是,先排序,然后头尾就是我们想要的;
ary.sort(function(a,b){return a-b})console.log(ary[0]);console.log(ary[ary.length-1]); js对象的深度克隆?
答:
function clone (Obj) { var buf; if (Obj instanceof Array) { buf = []; //创建一个空的数组 var i = Obj.length; while (i--) { buf[i] = clone(Obj[i]); } return buf; } else if (Obj instanceof Object) { buf = {}; //创建一个空对象 for (var k in Obj) { //为这个对象添加新的属性 buf[k] = clone(Obj[k]); } return buf; } else { return Obj; }} 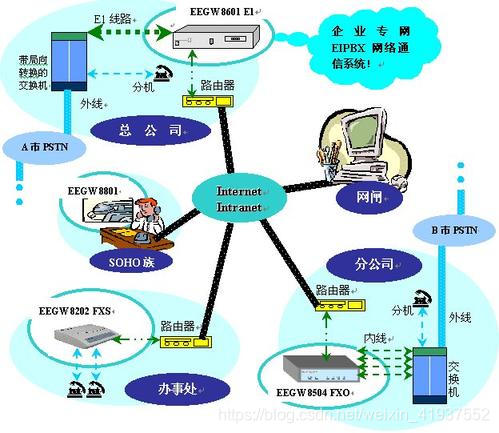
网络通信面试题
HTTP状态码及其含义?
答:
- 1XX :信息状态码
- 100 Continue 继续,⼀般在发送 post 请求时,已发送了 http header 之后服务端
- 将返回此信息,表示确认,之后发送具体参数信息
- 2XX :成功状态码
- 200 OK 正常返回信息
- 201 Created 请求成功并且服务器创建了新的资源
- 202 Accepted 服务器已接受请求,但尚未处理
- 3XX :重定向
- 301 Moved Permanently 请求的⽹⻚已永久移动到新位置。
- 302 Found 临时性重定向。
- 303 See Other 临时性重定向,且总是使⽤ GET 请求新的 URI 。
- 304 Not Modified ⾃从上次请求后,请求的⽹⻚未修改过。
- 4XX :客户端错误
- 400 Bad Request 服务器⽆法理解请求的格式,客户端不应当尝试再次使⽤相同的内
- 容发起请求。
- 401 Unauthorized 请求未授权。
- 403 Forbidden 禁⽌访问。
- 404 Not Found 找不到如何与 URI 相匹配的资源。
- 5XX: 服务器错误
- 500 Internal Server Error 最常⻅的服务器端错误。
- 503 Service Unavailable 服务器端暂时⽆法处理请求(可能是过载或维护)。
HTTP的⼏种请求⽅法⽤途?
答:
GET ⽅法
- 发送⼀个请求来取得服务器上的某⼀资源
POST ⽅法
- 向 URL 指定的资源提交数据或附加新的数据
PUT ⽅法
- 跟 POST ⽅法很像,也是想服务器提交数据。但是,它们之间有不同。 PUT 指定了资源在服务器上的位置,⽽ POST 没有
HEAD ⽅法
- 只请求⻚⾯的⾸部
DELETE ⽅法
- 删除服务器上的某资源
OPTIONS ⽅法
- 它⽤于获取当前 URL 所⽀持的⽅法。如果请求成功,会有⼀个 Allow 的头包含类似 “GET,POST” 这样的信息
TRACE ⽅法
- TRACE ⽅法被⽤于激发⼀个远程的,应⽤层的请求消息回路
CONNECT ⽅法
- 把请求连接转换到透明的 TCP/IP 通道
谈一下 WebSocket?
答:由于 http 存在⼀个明显的弊端(消息只能有客户端推送到服务器端,⽽服 务器端不能主动推送到客户端),导致如果服务器如果有连续的变化,这时只 能使⽤轮询,⽽轮询效率过低,并不适合。于是 WebSocket 被发明出来
相⽐与 http 具有以下有点
- ⽀持双向通信,实时性更强;
- 可以发送⽂本,也可以⼆进制⽂件;
- 协议标识符是 ws ,加密后是 wss ;
- 较少的控制开销。连接创建后, ws 客户端、服务端进⾏数据交换时,协议控制的数据包头部较⼩。在不包含头部的情况下,服务端到客户端的包头只有 2~10 字节(取决于数据包⻓度),客户端到服务端的的话,需要加上额外的4字节的掩码。⽽ HTTP 协议每次通信都需要携带完整的头部;
- ⽀持扩展。ws协议定义了扩展,⽤户可以扩展协议,或者实现⾃定义的⼦协议。(⽐如⽀
- 持⾃定义压缩算法等)
- ⽆跨域问题。
实现⽐较简单,服务端库如 socket.io 、 ws ,可以很好的帮助我们⼊⻔。
⽽客户端也只需要参照 api 实现即可
ajax、axios、fetch区别?
答:jQuery ajax
$.ajax({type: 'POST',url: url,data: data,dataType: dataType,success: function () {},error: function () {}}); 优缺点:
- 本身是针对 MVC 的编程,不符合现在前端 MVVM 的浪潮
- 基于原⽣的 XHR 开发, XHR 本身的架构不清晰,已经有了 fetch 的替代⽅案
- JQuery 整个项⽬太⼤,单纯使⽤ ajax 却要引⼊整个 JQuery ⾮常的不合理(采取个性化打包的⽅案⼜不能享受CDN服务
axios
axios({method: 'post',url: '/user/12345',data: {firstName: 'Fred',lastName: 'Flintstone'}}).then(function (response) {console.log(response);}).catch(function (error) {console.log(error);}); 优缺点:
- 从浏览器中创建 XMLHttpRequest
- 从 node.js 发出 http 请求
- ⽀持 Promise API
- 拦截请求和响应
- 转换请求和响应数据
- 取消请求
- ⾃动转换 JSON 数据
- 客户端⽀持防⽌ CSRF/XSRF
fetch
try {let response = await fetch(url);let data = response.json();console.log(data);} catch(e) {console.log("Oops, error", e);} 优缺点:
- fetcht 只对⽹络请求报错,对 400 , 500 都当做成功的请求,需要封装去处理
- fetch 默认不会带 cookie ,需要添加配置项
- fetch 不⽀持 abort ,不⽀持超时控制,使⽤ setTimeout 及 Promise.reject 的实现的超时控制并不能阻⽌请求过程继续在后台运⾏,造成了量的浪费
- fetch 没有办法原⽣监测请求的进度,⽽XHR可以
Ajax读取一个xml文档并进行解析的实例?
答案:
var xhr = new XMLHttpRequest;//->在IE7以下浏览器中是不兼容的xhr=new ActiveXObject("Microsoft.XMLHTTP");xhr=new ActiveXObject("Msxml2.XMLHTTP");xhr=new ActiveXObject("Msxml3.XMLHTTP"); //->惰性思想var getXHR = (function () { //->存放我们需要的几个获取Ajax对象的方法 var ajaxAry = [ function () { return new XMLHttpRequest; }, function () { return new ActiveXObject("Microsoft.XMLHTTP"); }, function () { return new ActiveXObject("Msxml2.XMLHTTP"); }, function () { return new ActiveXObject("Msxml3.XMLHTTP"); } ]; //->循环数组,把四个方法依次的执行 var xhr = null; for (var i = 0; i < ajaxAry.length; i++) { //->标准浏览器:i=0,获取的是第一个函数function(){return new XMLHttpRequest;}(A1),执行的时候没有报错,xhr是它的返回值也是我们的Ajax对象,没有报错不会走catch,执行getXHR = A1,这样把外面的getXHR重写了,遇到break循环结束 //->IE6浏览器:i=0,获取第一个函数执行,IE6不支持XMLHttpRequest,所以会报错,执行catch中的continue继续下一次的循环,i=1,获取第二个函数 function(){return new ActiveXObject("Microsoft.XMLHTTP");}(A2),执行没有报错,那么开始执行getXHR = A2,遇到break结束整个循环,此时外面的getXHR = A2 var tempFn = ajaxAry[i]; try { xhr = tempFn(); } catch (e) { continue; } getXHR = tempFn; break; } if (!xhr) { throw new Error("你的浏览器版本也太LOW了吧,还能不能愉快的玩耍~~"); } return getXHR;})();var xhr = getXHR();xhr.open("get", "test.txt?_=" + Math.random(), true);xhr.onreadystatechange = function () { if (xhr.readyState === 4 && /^2\d{2}$/.test(xhr.status)) { var val = xhr.responseText; console.log(val); }};xhr.send(null); 避免返回的数据是乱码的
->前端页面是UTF-8编码,如果我们从服务器请求回来的数据不是UTF-8编码格式,那么获取到的内容中,中文汉字会出现乱码
->需要我们使用”UTF-8到底的原则”:前端页面、JS、CSS、后台代码、数据库、请求传递的数据统一都采用一个编码UTF-8
->[RESPONSE] Content-Type:text/plain(纯文本)、application/json(JSON格式的)…设定响应主体中内容的格式
前端:设置请求头,获取响应头
->在前端的JS中我们可以使用 xhr.setRequestHeader([name],[value]) 设置请求头的信息;
可以使用 xhr.getResponseHeader([name])/xhr.getAllResponseHeaders() 获取响应头信息;
服务器端:获取请求头,设置响应头
->在NODE中我们可以使用 response.writeHead(200, {'content-type': 'application/json'}); 设置响应头信息
->在NODE中我们可以使用 request 这个对象获取到请求信息(起始行、首部、主体) 中的都可以获取到
多路复用与多路分解?
答:将传输层报文段中的数据交付到正确的套接字的工作被称为多路分解。
在源主机上从不同的套接字中收集数据,封装头信息生成报文段后,将报文段传递到网络层,这个过程被称为多路复用。
无连接的多路复用和多路分解指的是 UDP 套接字的分配过程,一个 UDP 套接字由一个二元组来标识,这个二元组包含了一 个目的地址和一个目的端口号。因此不同源地址和端口号的 UDP 报文段到达主机后,如果它们拥有相同的目的地址和目的端 口号,那么不同的报文段将会转交到同一个 UDP 套接字中。
面向连接的多路复用和多路分解指的是 TCP 套接字的分配过程,一个 TCP 套接字由一个四元组来标识,这个四元组包含了 源 IP 地址、源端口号、目的地址和目的端口号。因此,一个 TCP 报文段从网络中到达一台主机上时,该主机使用全部 4 个 值来将报文段定向到相应的套接字。
UDP 协议?
答:UDP 是一种无连接的,不可靠的传输层协议。它只提供了传输层需要实现的最低限度的功能,除了复用/分解功能和少量的差 错检测外,它几乎没有对 IP 增加其他的东西。UDP 协议适用于对实时性要求高的应用场景。
特点:
-
使用 UDP 时,在发送报文段之前,通信双方没有握手的过程,因此 UDP 被称为是无连接的传输层协议。因为没有握手 过程,相对于 TCP 来说,没有建立连接的时延。因为没有连接,所以不需要在端系统中保存连接的状态。
-
UDP 提供尽力而为的交付服务,也就是说 UDP 协议不保证数据的可靠交付。
-
UDP 没有拥塞控制和流量控制的机制,所以 UDP 报文段的发送速率没有限制。
-
因为一个 UDP 套接字只使用目的地址和目的端口来标识,所以 UDP 可以支持一对一、一对多、多对一和多对多的交互 通信。
-
UDP 首部小,只有 8 个字节。
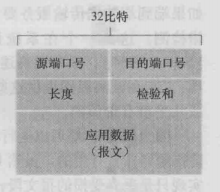
UDP 报文段结构
UDP 报文段由首部和应用数据组成。报文段首部包含四个字段,分别是源端口号、目的端口号、长度和检验和,每个字段的长 度为两个字节。长度字段指的是整个报文段的长度,包含了首部和应用数据的大小。校验和是 UDP 提供的一种差错校验机制。 虽然提供了差错校验的机制,但是 UDP 对于差错的恢复无能为力。
TCP 协议?
答:TCP 协议是面向连接的,提供可靠数据传输服务的传输层协议。
特点:
-
TCP 协议是面向连接的,在通信双方进行通信前,需要通过三次握手建立连接。它需要在端系统中维护双方连接的状态信息。
-
TCP 协议通过序号、确认号、定时重传、检验和等机制,来提供可靠的数据传输服务。
-
TCP 协议提供的是点对点的服务,即它是在单个发送方和单个接收方之间的连接。
-
TCP 协议提供的是全双工的服务,也就是说连接的双方的能够向对方发送和接收数据。
-
TCP 提供了拥塞控制机制,在网络拥塞的时候会控制发送数据的速率,有助于减少数据包的丢失和减轻网络中的拥塞程度。
-
TCP 提供了流量控制机制,保证了通信双方的发送和接收速率相同。如果接收方可接收的缓存很小时,发送方会降低发送 速率,避免因为缓存填满而造成的数据包的丢失。
TCP 报文段结构
TCP 报文段由首部和数据组成,它的首部一般为 20 个字节。
源端口和目的端口号用于报文段的多路复用和分解。
32 比特的序号和 32 比特的确认号,用与实现可靠数据运输服务。
16 比特的接收窗口字段用于实现流量控制,该字段表示接收方愿意接收的字节的数量。
4 比特的首部长度字段,该字段指示了以 32 比特的字为单位的 TCP 首部的长度。
6 比特的标志字段,ACK 字段用于指示确认序号的值是有效的,RST、SYN 和 FIN 比特用于连接建立和拆除。设置 PSH 字 段指示接收方应该立即将数据交给上层,URG 字段用来指示报文段里存在紧急的数据。
校验和提供了对数据的差错检测。

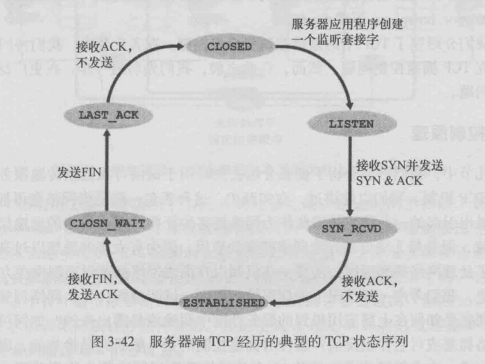
TCP 三次握手的过程
第一次握手,客户端向服务器发送一个 SYN 连接请求报文段,报文段的首部中 SYN 标志位置为 1,序号字段是一个任选的 随机数。它代表的是客户端数据的初始序号。
第二次握手,服务器端接收到客户端发送的 SYN 连接请求报文段后,服务器首先会为该连接分配 TCP 缓存和变量,然后向 客户端发送 SYN ACK 报文段,报文段的首部中 SYN 和 ACK 标志位都被置为 1,代表这是一个对 SYN 连接请求的确认, 同时序号字段是服务器端产生的一个任选的随机数,它代表的是服务器端数据的初始序号。确认号字段为客户端发送的序号加 一。
第三次握手,客户端接收到服务器的肯定应答后,它也会为这次 TCP 连接分配缓存和变量,同时向服务器端发送一个对服务 器端的报文段的确认。第三次握手可以在报文段中携带数据。
在我看来,TCP 三次握手的建立连接的过程就是相互确认初始序号的过程,告诉对方,什么样序号的报文段能够被正确接收。 第三次握手的作用是客户端对服务器端的初始序号的确认。如果只使用两次握手,那么服务器就没有办法知道自己的序号是否 已被确认。同时这样也是为了防止失效的请求报文段被服务器接收,而出现错误的情况。
TCP 四次挥手的过程
因为 TCP 连接是全双工的,也就是说通信的双方都可以向对方发送和接收消息,所以断开连接需要双方的确认。
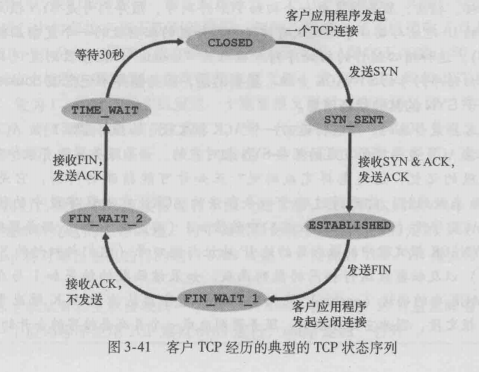
第一次挥手,客户端认为没有数据要再发送给服务器端,它就向服务器发送一个 FIN 报文段,申请断开客户端到服务器端的 连接。发送后客户端进入 FIN_WAIT_1 状态。
第二次挥手,服务器端接收到客户端释放连接的请求后,向客户端发送一个确认报文段,表示已经接收到了客户端释放连接的 请求,以后不再接收客户端发送过来的数据。但是因为连接是全双工的,所以此时,服务器端还可以向客户端发送数据。服务 器端进入 CLOSE_WAIT 状态。客户端收到确认后,进入 FIN_WAIT_2 状态。
第三次挥手,服务器端发送完所有数据后,向客户端发送 FIN 报文段,申请断开服务器端到客户端的连接。发送后进入 LAS T_ACK 状态。
第四次挥手,客户端接收到 FIN 请求后,向服务器端发送一个确认应答,并进入 TIME_WAIT 阶段。该阶段会持续一段时间, 这个时间为报文段在网络中的最大生存时间,如果该时间内服务端没有重发请求的话,客户端进入 CLOSED 的状态。如果收到 服务器的重发请求就重新发送确认报文段。服务器端收到客户端的确认报文段后就进入 CLOSED 状态,这样全双工的连接就被 释放了。
TCP 使用四次挥手的原因是因为 TCP 的连接是全双工的,所以需要双方分别释放到对方的连接,单独一方的连接释放,只代 表不能再向对方发送数据,连接处于的是半释放的状态。
最后一次挥手中,客户端会等待一段时间再关闭的原因,是为了防止发送给服务器的确认报文段丢失或者出错,从而导致服务器 端不能正常关闭。
状态转化图
ARQ 协议
ARQ 协议指的是自动重传请求,它通过超时和重传来保证数据的可靠交付,它是 TCP 协议实现可靠数据传输的一个很重要的 机制。
它分为停止等待 ARQ 协议和连续 ARQ 协议。
一、停止等待 ARQ 协议
停止等待 ARQ 协议的基本原理是,对于发送方来说发送方每发送一个分组,就为这个分组设置一个定时器。当发送分组的确认 回答返回了,则清除定时器,发送下一个分组。如果在规定的时间内没有收到已发送分组的肯定回答,则重新发送上一个分组。
对于接受方来说,每次接受到一个分组,就返回对这个分组的肯定应答,当收到冗余的分组时,就直接丢弃,并返回一个对冗余 分组的确认。当收到分组损坏的情况的时候,直接丢弃。
使用停止等待 ARQ 协议的缺点是每次发送分组必须等到分组确认后才能发送下一个分组,这样会造成信道的利用率过低。
二、连续 ARQ 协议
连续 ARQ 协议是为了解决停止等待 ARQ 协议对于信道的利用率过低的问题。它通过连续发送一组分组,然后再等待对分组的 确认回答,对于如何处理分组中可能出现的差错恢复情况,一般可以使用滑动窗口协议和选择重传协议来实现。
- 滑动窗口协议
使用滑动窗口协议,在发送方维持了一个发送窗口,发送窗口以前的分组是已经发送并确认了的分组,发送窗口中包含了已经发 送但未确认的分组和允许发送但还未发送的分组,发送窗口以后的分组是缓存中还不允许发送的分组。当发送方向接收方发送分 组时,会依次发送窗口内的所有分组,并且设置一个定时器,这个定时器可以理解为是最早发送但未收到确认的分组。如果在定 时器的时间内收到某一个分组的确认回答,则滑动窗口,将窗口的首部移动到确认分组的后一个位置,此时如果还有已发送但没 有确认的分组,则重新设置定时器,如果没有了则关闭定时器。如果定时器超时,则重新发送所有已经发送但还未收到确认的分 组。
接收方使用的是累计确认的机制,对于所有按序到达的分组,接收方返回一个分组的肯定回答。如果收到了一个乱序的分组,那 么接方会直接丢弃,并返回一个最近的按序到达的分组的肯定回答。使用累计确认保证了确认号以前的分组都已经按序到达了, 所以发送窗口可以移动到已确认分组的后面。
滑动窗口协议的缺点是因为使用了累计确认的机制,如果出现了只是窗口中的第一个分组丢失,而后面的分组都按序到达的情况 的话,那么滑动窗口协议会重新发送所有的分组,这样就造成了大量不必要分组的丢弃和重传。
- 选择重传协议
因为滑动窗口使用累计确认的方式,所以会造成很多不必要分组的重传。使用选择重传协议可以解决这个问题。
选择重传协议在发送方维护了一个发送窗口。发送窗口的以前是已经发送并确认的分组,窗口内包含了已发送但未被确认的分组, 已确认的乱序分组,和允许发送但还未发送的分组,发送窗口以后的是缓存中还不允许发送的分组。选择重传协议与滑动窗口协 议最大的不同是,发送方发送分组时,为一个分组都创建了一个定时器。当发送方接受到一个分组的确认应答后,取消该分组的 定时器,并判断接受该分组后,是否存在由窗口首部为首的连续的确认分组,如果有则向后移动窗口的位置,如果没有则将该分 组标识为已接收的乱序分组。当某一个分组定时器到时后,则重新传递这个分组。
在接收方,它会确认每一个正确接收的分组,不管这个分组是按序的还是乱序的,乱序的分组将被缓存下来,直到所有的乱序分 组都到达形成一个有序序列后,再将这一段分组交付给上层。对于不能被正确接收的分组,接收方直接忽略该分组。
TCP 的可靠运输机制
TCP 的可靠运输机制是基于连续 ARQ 协议和滑动窗口协议的。
TCP 协议在发送方维持了一个发送窗口,发送窗口以前的报文段是已经发送并确认了的报文段,发送窗口中包含了已经发送但 未确认的报文段和允许发送但还未发送的报文段,发送窗口以后的报文段是缓存中还不允许发送的报文段。当发送方向接收方发 送报文时,会依次发送窗口内的所有报文段,并且设置一个定时器,这个定时器可以理解为是最早发送但未收到确认的报文段。 如果在定时器的时间内收到某一个报文段的确认回答,则滑动窗口,将窗口的首部向后滑动到确认报文段的后一个位置,此时如 果还有已发送但没有确认的报文段,则重新设置定时器,如果没有了则关闭定时器。如果定时器超时,则重新发送所有已经发送 但还未收到确认的报文段,并将超时的间隔设置为以前的两倍。当发送方收到接收方的三个冗余的确认应答后,这是一种指示, 说明该报文段以后的报文段很有可能发生丢失了,那么发送方会启用快速重传的机制,就是当前定时器结束前,发送所有的已发 送但确认的报文段。
接收方使用的是累计确认的机制,对于所有按序到达的报文段,接收方返回一个报文段的肯定回答。如果收到了一个乱序的报文 段,那么接方会直接丢弃,并返回一个最近的按序到达的报文段的肯定回答。使用累计确认保证了返回的确认号之前的报文段都 已经按序到达了,所以发送窗口可以移动到已确认报文段的后面。
发送窗口的大小是变化的,它是由接收窗口剩余大小和网络中拥塞程度来决定的,TCP 就是通过控制发送窗口的长度来控制报文 段的发送速率。
但是 TCP 协议并不完全和滑动窗口协议相同,因为许多的 TCP 实现会将失序的报文段给缓存起来,并且发生重传时,只会重 传一个报文段,因此 TCP 协议的可靠传输机制更像是窗口滑动协议和选择重传协议的一个混合体。
TCP 的流量控制机制
TCP 提供了流量控制的服务,这个服务的主要目的是控制发送方的发送速率,保证接收方来得及接收。因为一旦发送的速率大 于接收方所能接收的速率,就会造成报文段的丢失。接收方主要是通过接收窗口来告诉发送方自己所能接收的大小,发送方根据 接收方的接收窗口的大小来调整发送窗口的大小,以此来达到控制发送速率的目的。
TCP 的拥塞控制机制
TCP 的拥塞控制主要是根据网络中的拥塞情况来控制发送方数据的发送速率,如果网络处于拥塞的状态,发送方就减小发送的 速率,这样一方面是为了避免继续增加网络中的拥塞程度,另一方面也是为了避免网络拥塞可能造成的报文段丢失。
TCP 的拥塞控制主要使用了四个机制,分别是慢启动、拥塞避免、快速重传和快速恢复。
慢启动的基本思想是,因为在发送方刚开始发送数据的时候,并不知道网络中的拥塞程度,所以先以较低的速率发送,进行试探 ,每次收到一个确认报文,就将发动窗口的长度加一,这样每个 RTT 时间后,发送窗口的长度就会加倍。当发送窗口的大小达 到一个阈值的时候就进入拥塞避免算法。
拥塞避免算法是为了避免可能发生的拥塞,将发送窗口的大小由每过一个 RTT 增长一倍,变为每过一个 RTT ,长度只加一。 这样将窗口的增长速率由指数增长,变为加法线性增长。
快速重传指的是,当发送方收到三个冗余的确认应答时,因为 TCP 使用的是累计确认的机制,所以很有可能是发生了报文段的 丢失,因此采用立即重传的机制,在定时器结束前发送所有已发送但还未接收到确认应答的报文段。
快速恢复是对快速重传的后续处理,因为网络中可能已经出现了拥塞情况,所以会将慢启动的阀值减小为原来的一半,然后将拥 塞窗口的值置为减半后的阀值,然后开始执行拥塞避免算法,使得拥塞窗口缓慢地加性增大。简单来理解就是,乘性减,加性增。
TCP 认为网络拥塞的主要依据是报文段的重传次数,它会根据网络中的拥塞程度,通过调整慢启动的阀值,然后交替使用上面四 种机制来达到拥塞控制的目的。
Post 和 Get 的区别?
答:Post 和 Get 是 HTTP 请求的两种方法。
-
(1)从应用场景上来说,GET 请求是一个幂等的请求,一般 Get 请求用于对服务器资源不会产生影响的场景,比如说请求一个网页。而 Post 不是一个幂等的请求,一般用于对服务器资源会产生影响的情景。比如注册用户这一类的操作。
-
(2)因为不同的应用场景,所以浏览器一般会对 Get 请求缓存,但很少对 Post 请求缓存。
-
(3)从发送的报文格式来说,Get 请求的报文中实体部分为空,Post 请求的报文中实体部分一般为向服务器发送的数据。
-
(4)但是 Get 请求也可以将请求的参数放入 url 中向服务器发送,
- 这样的做法相对于 Post 请求来说,一个方面是不太安全,因为请求的 url 会被保留在历史记录中。并且浏览器由于对 url 有一个长度上的限制,所以会影响 get 请求发送数据时的长度。这个限制是浏览器规定的,并不是 RFC 规定的。还有就是 post 的参数传递支持更多的数据类型。
DNS 为什么使用 UDP 协议作为传输层协议?
答:DNS 使用 UDP 协议作为传输层协议的主要原因是为了避免使用 TCP 协议时造成的连接时延。
因为为了得到一个域名的 IP 地址,往往会向多个域名服务器查询,如果使用 TCP 协议,那么每次请求都会存在连接时延,这样使 DNS 服务变得很慢,因为大多数的地址查询请求,都是浏览器请求页面时发出的,这样会造成网页的等待时间过长。
使用 UDP 协议作为 DNS 协议会有一个问题,由于历史原因,物理链路的最小MTU = 576,所以为了限制报文长度不超过576,UDP 的报文段的长度被限制在 512 个字节以内,这样一旦 DNS 的查询或者应答报文,超过了 512 字节,那么基于 UDP 的DNS 协议就会被截断为 512 字节,那么有可能用户得到的 DNS 应答就是不完整的。这里 DNS 报文的长度一旦超过限制,并不会像 TCP 协议那样被拆分成多个报文段传输,因为 UDP 协议不会维护连接状态,所以我们没有办法确定那几个报文段属于同一个数据,UDP 只会将多余的数据给截取掉。
为了解决这个问题,我们可以使用 TCP 协议去请求报文。
DNS 还存在的一个问题是安全问题,就是我们没有办法确定我们得到的应答,一定是一个安全的应答,因为应答可以被他人伪造,所以现在有了 DNS over HTTPS 来解决这个问题。
谈谈 CDN 服务?
答:CDN 是一个内容分发网络,通过对源网站资源的缓存,利用本身多台位于不同地域、不同运营商的服务器,向用户提供资就近访问的 功能。也就是说,用户的请求并不是直接发送给源网站,而是发送给 CDN 服务器,由 CND 服务器将请求定位到最近的含有该资源 的服务器上去请求。这样有利于提高网站的访问速度,同时通过这种方式也减轻了源服务器的访问压力。
什么是正向代理和反向代理?
答:我们常说的代理也就是指正向代理,正向代理的过程,它隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的 服务都被代理服务器代替来请求。
反向代理隐藏了真实的服务端,当我们请求一个网站的时候,背后可能有成千上万台服务器为我们服务,但具体是哪一台,我们不知 道,也不需要知道,我们只需要知道反向代理服务器是谁就好了,反向代理服务器会帮我们把请求转发到真实的服务器那里去。反向 代理器一般用来实现负载平衡。
负载平衡的两种实现方式?
答:一种是使用反向代理的方式,用户的请求都发送到反向代理服务上,然后由反向代理服务器来转发请求到真实的服务器上,以此来实 现集群的负载平衡。
另一种是 DNS 的方式,DNS 可以用于在冗余的服务器上实现负载平衡。因为现在一般的大型网站使用多台服务器提供服务,因此一 个域名可能会对应多个服务器地址。当用户向网站域名请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合,但在 每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。以此将用户的请求均衡的分配到各个不同的服 务器上,这样来实现负载均衡。这种方式有一个缺点就是,由于 DNS 服务器中存在缓存,所以有可能一个服务器出现故障后,域名解 析仍然返回的是那个 IP 地址,就会造成访问的问题。
即时通讯的实现,短轮询、长轮询、SSE 和 WebSocket 间的区别?
答:短轮询和长轮询的目的都是用于实现客户端和服务器端的一个即时通讯。
短轮询的基本思路就是浏览器每隔一段时间向浏览器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行 响应。这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客 户端能够模拟实时地收到服务器端的数据的变化。这种方式的优点是比较简单,易于理解。缺点是这种方式由于需要不断的建立 ht tp 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
长轮询的基本思路是,首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将 这个请求挂起,然后判断服务器端数据是否有更新。如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。 客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。长轮询和短轮询比起来,它的 优点是明显减少了很多不必要的 http 请求次数,相比之下节约了资源。长轮询的缺点在于,连接挂起也会导致资源的浪费。
SSE 的基本思想是,服务器使用流信息向服务器推送信息。严格地说,http 协议无法做到服务器主动推送信息。但是,有一种变通 方法,就是服务器向客户端声明,接下来要发送的是流信息。也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断 地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流,视频播放就是这样的例子。SSE 就是利用这种机 制,使用流信息向浏览器推送信息。它基于 http 协议,目前除了 IE/Edge,其他浏览器都支持。它相对于前面两种方式来说,不 需要建立过多的 http 请求,相比之下节约了资源。
上面三种方式本质上都是基于 http 协议的,我们还可以使用 WebSocket 协议来实现。WebSocket 是 Html5 定义的一个新协 议,与传统的 http 协议不同,该协议允许由服务器主动的向客户端推送信息。使用 WebSocket 协议的缺点是在服务器端的配置 比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息,而 SSE 的方式是单向通信的,只能 由服务器端向客户端推送信息,如果客户端需要发送信息就是属于下一个 http 请求了。
实现一个页面操作不会整页刷新的网站,并且能在浏览器前进、后退时正确响应。给出你的技术实现方案?
答:相较于不同页面的跳转,AJAX可以说大大提高了用户的浏览体验,不用看到页面切换之间的白屏是件很惬意的事情。但是很多早先的AJAX应用是不支持浏览器的前进后退的,这导致了用户不管在网站里浏览到何处,一旦刷新就会立刻回到起初的位置,并且用户也无法通过浏览器的前进后退按钮来实现浏览历史的切换。
对于第一个问题,解决还算容易,只要用cookie或者localStorage来记录应用的状态即可,刷新页面时读取一下这个状态,然后发送相应ajax请求来改变页面即可。但是第二个问题就很麻烦了,先说下现代浏览器的解决方案。

jQuery 面试题
jquery 特点,聊一聊 jquery?
答:
- jQuery 是一款轻量级的 js 框架,jQuery 核心 js 文件才几十 kb,不会影响页面加载速度。与 Extjs 相比要轻便的多。
- jQuery 的选择器用起来很方便,好比说我要找到某个 dom 对象的相邻元素 js 可能要写好几行代码,而 jQuery 一行代码就搞定了,再比如我要将一个表格的隔行变色,jQuery 也是一行代码搞定。
- jQuery 的链式操作可以把多个操作写在一行代码里。
- jQuery 还简化了 js 操作 css 的代码,并且代码的可读性也比 js 要强。
- jQuery 简化了 AJAX 操作,后台只需返回一个 JSON 格式的字符串就能完成与前台的通信。
- jQuery 基本兼容了现在主流的浏览器,不用再为浏览器的兼容问题而伤透脑筋。
- jQuery 有着丰富的第三方的插件,例如:树形菜单、日期控件、图片切换插件、弹出窗口等等基本前台页面上的组件都有对应插件,并且用 jQuery 插件做出来的效果很炫,并且可以根据自己需要去改写和封装插件,简单实用。
- jQuery 可扩展性强,jQuery 提供了扩展接口:jQuery.extend(object), 可以在 jQuery 的命名空间上增加新函数。jQuery 的所有插件都是基于这个扩展接口开发的。
jquery 对象和 dom 对象怎么转换的?
答:
[0]可以转化为 DOM 对象$(domObject)可以转化为 jQuery 对象
jquery 中如何将数组转化为 json 字符串,然后再转化回来?
答:
$.fn.stringifyArray = function(array) { return JSON.stringify(array) } $.fn.parseArray = function(array) { return JSON.parse(array) } 然后调用:
$("").stringifyArray(array) jQuery 的源码看过吗?能不能简单概况一下它的实现原理?
答:
1、闭包机制;
// 以下截取自 jquery 源码片段(function( window, undefined ) {/* 源码内容 */})( window ); 上面这一小段代码来自于 1.9.0 当中 jquery 的源码,它是一个无污染的 JS 插件的标准写法,专业名词叫闭包。可以把它简单的看做是一个函数,与普通函数不同的是,这个函数没有名字,而且会立即执行
我们将里面的变量变成了局域变量,这不仅可以提高运行速度,更重要的是我们在引用 jquery 的 JS 文件时,不会因为 jquery 当中的变量太多,而与其它的 JS 框架的变量命名产生冲突;闭包中的变量声明没有污染到外面的全局变量;;
2、作为全局的一个属性;
window.jQuery = window.$ = jQuery;
这一句话将我们在闭包当中定义的 jQuery 对象导出为全局变量 jQuery 和 $,因此我们才可以在外部直接使用 jQuery 和 $。
window 是默认的 JS 上下文环境,因此将对象绑定到 window 上面,就相当于变成了传统意义上的全局变量,
3、最核心的功能,就是选择器;
首先我们进入 jquery 源码中,可以很容易的找到 jquery 对象的声明,看过以后会发现,原来我们的 jquery 对象就是 init 对象。
jQuery = function( selector, context ) { return new jQuery.fn.init( selector, context, rootjQuery ); } 这里出现了 jQuery.fn 这样一个东西,它的由来可以在 jquery 的源码中找到,它其实代表的就是 jQuery 对象的原型。
jQuery.fn = jQuery.prototype; jQuery.fn.init.prototype = jQuery.fn;
这两句话,第一句把 jQuery 对象的原型赋给了 fn 属性,第二句把 jQuery 对象的原型又赋给了 init 对象的原型。也就是说,init 对象和 jQuery 具有相同的原型,因此我们在上面返回的 init 对象,就与 jQuery 对象有一样的属性和方法。
我们不打算深究 init 这个方法的逻辑以及实现,但是我们需要知道的是,jQuery 其实就是将 DOM 对象加了一层包裹,而寻找某个或者若干个 DOM 对象是由 sizzle 选择器负责的,
jQuery 对象有很多的属性和方法;对于属性来说,我们最需要关注的只有一个属性,就是 [0] 属性,[0] 其实就是原生的 DOM 对象。
很多时候,我们在 jQuery 和 DOM 对象之间切换时需要用到 [0] 这个属性。
从截图也可以看出,jQuery 对象其实主要就是把原生的 DOM 对象存在了 [0] 的位置,并给它加了一系列简便的方法。
这个索引 0 的属性我们可以从一小段代码简单的看一下它的由来,下面是 init 方法中的一小段对 DOMElement 对象作为选择器的源码。
// Handle $(DOMElement) if ( selector.nodeType ) { /* 可以看到,这里将 DOM 对象赋给了 jQuery 对象的 [0] 这个位置 */ this.context = this[0] = selector; this.length = 1; return this; } 这一小段代码可以在 jquery 源码中找到,它是处理传入的选择参数是一个 DOM 对象的情况。
可以看到,里面很明显的将 jQuery 对象索引 0 的位置以及 context 属性,都赋予了 DOM 对象
。代码不仅说明了这一点,也同时说明了,我们使用 $(DOMElement) 可以将一个 DOM 对象转换为 jQuery 对象,从而通过转换获得 jQuery 对象的简便方法。
4、ready 方法
$(function(){}) 或者是 ready 方法;
实现类似 jquery 的 ready 方法的效果我们是可以简单做到的,它的实现原理就是,维护一个函数数组,然后不停的判断 DOM 是否加载完毕,倘若加载完毕就触发所有数组中的函数。
遵循着这一思想,LZ 拿出很久之前写的一个小例子,来给各位看一下。
(function( window, undefined ) {var jQuery = {isReady:false,// 文档加载是否完成的标识readyList:[],// 函数序列//onload 事件实现ready : function(fn){// 如果是函数,加入到函数序列if(fn && typeof fn == 'function' ){jQuery.readyList.push(fn);}// 文档加载完成,执行函数序列。if(jQuery.isReady){for(var i = 0;i < jQuery.readyList.length ;i++){fn = jQuery.readyList[i];jQuery.callback(fn);}return jQuery;}},// 回调callback : function(fn){fn.call(document,jQuery);}};// 导出对象window.$ = window.jQuery = jQuery;// 判断加载是否完成var top = false;try {top = window.frameElement == null && document.documentElement;} catch(e) {}if ( top && top.doScroll ) {(function doScrollCheck() {try {top.doScroll("left");jQuery.isReady = true;jQuery.ready();} catch(e) {setTimeout( doScrollCheck, 50 );}})();}}(window)); 这段代码是 LZ 从之前的例子摘出来的,它的实现逻辑非常简单,但是可以达到 jQuery 的 ready 方法的效果,
5、extend 方法
简单说两个 extend 方法的常用方式。
- 1、使用 jQuery.fn.extend 可以扩展 jQuery 对象,使用 jQuery.extend 可以扩展 jQuery,前者类似于给类添加普通方法,后者类似于给类添加静态方法。
- 2、两个 extend 方法如果有两个 object 类型的参数,则会将后面的参数对象属性扩展到第一个参数对象上面,扩展时可以再添加一个 boolean 参数控制是否深度拷贝。
jquery find,children,filter 的区别?
答:
- filter 是对自身集合元素的操作,
- children 是对子元素的检索,
- find 是对它的后代元素的检索操作
.children(selector) 方法是返回匹配元素集合中每个元素的所有子元素(仅儿子辈)。参数可选,添加参数表示通过选择器进行过滤,对元素进行筛选。
.find(selector) 方法是返回匹配元素集合中每个元素的后代。参数是必选的,可以为选择器、jquery 对象可元素来对元素进行筛选。
.find() 与 .children() 方法类似,不同的是后者仅沿着 DOM 树向下遍历单一层级。这里的 children,我理解为儿子,只在儿子这一级遍历。
jQuery 的队列是如何实现的?队列可以用在哪些地方?
答:jQuery 核心中,有一组队列控制方法,这组方法由 queue()/dequeue()/clearQueue() 三个方法组成,它对需要连续按序执行的函数的控制可以说是简明自如,主要应用于 animate () 方法,ajax 以及其他要按时间顺序执行的事件中。
先解释一下这组方法各自的含义。
queue(name,[callback]): 当只传入一个参数时,它返回并指向第一个匹配元素的队列(将是一个函数数组,队列名默认是 fx); 当有两个参数传入时,第一个参数还是默认为 fx 的的队列名,第二个参数又分两种情况,当第二个参数是一个函数时,它将在匹配的元素的队列最后添加一个函数。当第二个参数是一个函数数组时,它将匹配元素的队列用新的一个队列来代替(函数数组). 可能,这个理解起来有点晕。
dequeue(name): 这个好理解,就是从队列最前端移除一个队列函数,并执行它。
clearQueue([queueName]): 这是 1.4 新增的方法。清空对象上尚未执行的所有队列。参数可选,默认为 fx. 但个人觉得这个方法没多大用,用 queue() 方法传入两个参数的第二种参数即可实现 clearQueue 方法。
现在,我们要实现这样一个效果,有标有 1 至 7 的数字方块,要求这七个方块自左到右依次下落;写好以后
;如果此时,你想调换一个某个的执行顺序,比如,你想让 5 落下后再开始下落 3, 或者新加 8 至 15 八个方块,怎么办?
重写吗?在里面小心冀冀的改吗?显然,我们需要另外一种列简明便捷的方法来实现这个效果,那就是 jQuery 队列控制方法。;
这样一来,看起来是不是简明多了。如何实现?
- 新建一个数组,把动画函数依次放进去(这样更改顺序,新加动画是不是方便多了?);
- 用 queue 将这组动画函数数组加入到 slideList 队列中;
- 用 dequeue 取出 slideList 队列中第一个函数,并执行它;
- 初始执行第一个函数。
至于 clearQueue() 方法,就不多说了,演示中停止按钮调用的就是 clearQueue() 方法,当然你还可以用 queue() 方法直接将现在的函数列队替换成 [] 空数组实现(个人比较推荐空数组替换。, 更直观).
jQuery 与 jQuery UI 有啥区别?
答:
- jQuery 是一个 js 库,主要提供的功能是选择器,属性修改和事件绑定等等。
- jQuery UI 则是在 jQuery 的基础上,利用 jQuery 的扩展性,设计的插件。
- 提供了一些常用的界面元素,诸如对话框、拖动行为、改变大小行为等等
jQuery 和 Zepto 的区别?各自的使用场景?
答:zepto 主要用在移动设备上,只支持较新的浏览器,好处是代码量比较小,性能也较好。
jquery 主要是兼容性好,可以跑在各种 pc,移动上,好处是兼容各种浏览器,缺点是代码量大,同时考虑兼容,性能也不够好。
jq 自身也注意到了这个总是,所有它的 2.x 版本是不支持 ie6 7 8 的
针对 jQuery 性能的优化方法?
答:
- 基于 Class 的选择性的性能相对于 Id 选择器开销很大,因为需遍历所有 DOM 元素。
- 频繁操作的 DOM,先缓存起来再操作。用 jQuery 的链式调用更好。
- 比如:
var str=$("a").attr("href");
- 比如:
-
for 循环
for (var i = size; i < arr.length; i++) {}
for 循环每一次循环都查找了数组 (arr) 的 length 属性,在开始循环的时候设置一个变量来存储这个数字,可以让循环跑得更快:
for (var i = size, length = arr.length; i < length; i++) { } jQuery 一个对象可以同时绑定多个事件,这是如何实现的?
答:
$ele.on('eventName', handle1); $ele.on('eventName', handle2); $ele.on('eventName', handle3); 其实 $ele 元素的 eventName 事件有一个处理函数数组 监听一次就往里面放一个 handle,数组是先进后出型的
也就是栈, 然后触发事件的时候一次执行
上面的监听相当于
$ele.eventHandle['eventName'] = []; $ele.eventHandle['eventName'].push(handle1); $ele.eventHandle['eventName'].push(handle2); $ele.eventHandle['eventName'].push(handle3);
然后 $ele.trigger('eventName') 触发的时候, 从栈里面取出处理函数执行
while($ele.eventHandle['eventName'].length) { handle = $ele.eventHandle['eventName'].pop(); handle(); } 最先监听的最后执行;

Vue.js 面试题
Vue.js 路由的钩⼦函数?
答:首页可以控制导航跳转, beforeEach , afterEach 等,⼀般⽤于页⾯ title 的修改。⼀些需要登录才能调整⻚⾯的重定向功能。
- beforeEach 主要有3个参数 to , from , next 。
- to : route 即将进⼊的⽬标路由对象。
- from : route 当前导航正要离开的路由。
- next : function ⼀定要调⽤该⽅法 resolve 这个钩⼦。执⾏效果依赖next ⽅法的调⽤参数。可以控制网页的跳转
vuex是什么?怎么使⽤?哪种功能场景使⽤它?
答:
- 只⽤来读取的状态集中放在 store 中; 改变状态的⽅式是提交 mutations ,这是个同步的事物; 异步逻辑应该封装在 action 中。
- 在 main.js 引⼊ store ,注⼊。新建了⼀个⽬录 store , … export
- 场景有:单⻚应⽤中,组件之间的状态、⾳乐播放、登录状态、加⼊购物⻋
- state : Vuex 使⽤单⼀状态树,即每个应⽤将仅仅包含⼀个 store 实例,但单⼀状态
- 树和模块化并不冲突。存放的数据状态,不可以直接修改⾥⾯的数据。
- mutations : mutations 定义的⽅法动态修改 Vuex 的 store 中的状态或数据
- getters :类似 vue 的计算属性,主要⽤来过滤⼀些数据。
- action : actions 可以理解为通过将 mutations ⾥⾯处⾥数据的⽅法变成可异步的处理数据的⽅法,简单的说就是异步操作数据。 view 层通过 store.dispath 来分发 action
- modules :项⽬特别复杂的时候,可以让每⼀个模块拥有⾃⼰的 state 、mutation 、 action 、 getters ,使得结构⾮常清晰,⽅便管理
Vue.js 如何让CSS只在当前组件中起作⽤?
答:将当前组件的 <style> 修改为 <style scoped>
Vue.js 指令v-el的作⽤是什么?
答:提供⼀个在页⾯上已存在的 DOM 元素作为 Vue 实例的挂载⽬标.可以是 CSS 选择器,也可以是⼀个 HTMLElement 实例,
在 Vue.js 中使⽤插件的步骤?
答:
- 采⽤ ES6 的 import … from … 语法或 CommonJS 的 require() ⽅法引⼊插件
- 使⽤全局⽅法 Vue.use( plugin ) 使⽤插件,可以传⼊⼀个选项对象 Vue.use(MyPlugin, { someOption: true })
Vue.js 路由之间跳转?
答:声明式(标签跳转)
编程式( js跳转)
router.push('index') Vue.js 组件中 data 什么时候可以使⽤对象?
答:组件复⽤时所有组件实例都会共享 data ,如果 data 是对象的话,就会造成⼀个组件 修改 data 以后会影响到其他所有组件,所以需要将 data 写成函数,每次⽤到就调⽤ ⼀次函数获得新的数据。当我们使⽤ new Vue() 的⽅式的时候,⽆论我们将 data 设置为对象还是函数都是可 以的,因为 new Vue() 的⽅式是⽣成⼀个根组件,该组件不会复⽤,也就不存在共享 data 的情况了
Vue-Router 中导航守卫有哪些?
答:完整的导航解析流程
- 导航被触发。
- 在失活的组件里调用离开守卫。
- 调用全局的
beforeEach守卫。 - 在重用的组件里调用
beforeRouteUpdate守卫 (2.2+)。 - 在路由配置里调用
beforeEnter。 - 解析异步路由组件。
- 在被激活的组件里调用
beforeRouteEnter。 - 调用全局的
beforeResolve守卫 (2.5+)。 - 导航被确认。
- 调用全局的
afterEach钩子。 - 触发 DOM 更新。
- 用创建好的实例调用
beforeRouteEnter守卫中传给next的回调函数。
Vue.js ajax 请求放在哪个生命周期中?
答:
- 在created的时候,视图中的
dom并没有渲染出来,所以此时如果直接去操dom节点,无法找到相关的元素 - 在mounted中,由于此时
dom已经渲染出来了,所以可以直接操作dom节点
一般情况下都放到mounted中,保证逻辑的统一性,因为生命周期是同步执行的,ajax是异步执行的
Vue.js 中相同逻辑如何抽离?
答:Vue.mixin用法 给组件每个生命周期,函数等都混入一些公共逻辑
Vue.mixin = function (mixin: Object) { this.options = mergeOptions(this.options, mixin); // 将当前定义的属性合并到每个组件中 return this } export function mergeOptions ( parent: Object, child: Object, vm?: Component ): Object { if (!child._base) { if (child.extends) { // 递归合并extends parent = mergeOptions(parent, child.extends, vm) } if (child.mixins) { // 递归合并mixin for (let i = 0, l = child.mixins.length; i < l; i++) { parent = mergeOptions(parent, child.mixins[i], vm) } } } const options = {} // 属性及生命周期的合并 let key for (key in parent) { mergeField(key) } for (key in child) { if (!hasOwn(parent, key)) { mergeField(key) } } function mergeField (key) { const strat = strats[key] || defaultStrat // 调用不同属性合并策略进行合并 options[key] = strat(parent[key], child[key], vm, key) } return options } Vue.js 中常见性能优化?
答:1.编码优化:
-
1.不要将所有的数据都放在data中,data中的数据都会增加getter和setter,会收集对应的watcher
-
2.
vue在 v-for 时给每项元素绑定事件需要用事件代理 -
3.
SPA页面采用keep-alive缓存组件 -
4.拆分组件( 提高复用性、增加代码的可维护性,减少不必要的渲染 )
-
5.
v-if当值为false时内部指令不会执行,具有阻断功能,很多情况下使用v-if替代v-show -
6.
key保证唯一性 ( 默认vue会采用就地复用策略 ) -
7.
Object.freeze冻结数据 -
8.合理使用路由懒加载、异步组件
-
9.尽量采用runtime运行时版本
-
10.数据持久化的问题 (防抖、节流)
2.Vue加载性能优化:
- 第三方模块按需导入 (
babel-plugin-component) -
滚动到可视区域动态加载 ( )
-
图片懒加载 ()
3.用户体验:
app-skeleton骨架屏app-shellapp壳pwa
4.SEO优化:
- 预渲染插件
prerender-spa-plugin - 服务端渲染
ssr
5.打包优化:
- 使用
cdn的方式加载第三方模块 - 多线程打包
happypack splitChunks抽离公共文件sourceMap生成
6.缓存,压缩
- 客户端缓存、服务端缓存
- 服务端
gzip压缩
谈一下你对 Vue.js 的 MVVM 原理的理解?
答:传统MVC
传统的MVC指的是
- M是指业务模型,Model(模型)
- V是指用户界面,View(视图)
- C则是控制器,Controller(控制器)
使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。
用户操作会请求服务端路由,路由会调用对应的控制器来处理,控制器会获取数据。将结果返回给前端,页面重新渲染
MVVM
MVVM 是 Model-View-ViewModel 的缩写
- Model 代表数据模型,也可以在 Model 中定义数据修改和操作的业务逻辑。
- View 代表 UI 组件,它负责将数据模型转化成 UI 展现出来。
- ViewModel 监听模型数据的改变和控制视图⾏为、处理⽤户交互,简单理解就是⼀个同步View 和 Model 的对象,连接 Model 和 View
传统的前端会将数据手动渲染到页面上,MVVM模式不需要用户手动操作dom元素;
将数据绑定到viewModel层上,会自动将数据渲染到页面中,视图变化会通知viewModel层更新数据。
ViewModel就是我们MVVM模式中的桥梁.
在 MVVM 架构下, View 和 Model 之间并没有直接的联系,⽽是通过 ViewModel 进⾏交互, Model 和 ViewModel 之间的交互是双向的, 因 此 View 数据的变化会同步到Model中,⽽Model 数据的变化也会⽴即反 应到 View 上。
ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,⽽ View 和 Model 之间的同步⼯作完全是⾃动的,⽆需⼈为⼲涉,因此开 发者只需关注业务逻辑,不需要⼿动操作DOM,不需要关注数据状态的同 步问题,复杂的数据状态维护完全由 MVVM 来统⼀管理。
请说一下 Vue.js 响应式数据的原理?
答:
- 1. 核心点:
Object.defineProperty - 2. 默认
Vue在初始化数据时,会给data中的属性使用Object.defineProperty重新定义所有属性,当页面取到对应属性时。会进行依赖收集(收集当前组件的watcher) 如果属性发生变化会通知相关依赖进行更新操作。
Object.defineProperty(obj, key, { enumerable: true, configurable: true, get: function reactiveGetter () { const value = getter ? getter.call(obj) : val if (Dep.target) { dep.depend() // ** 收集依赖 ** / if (childOb) { childOb.dep.depend() if (Array.isArray(value)) { dependArray(value) } } } return value }, set: function reactiveSetter (newVal) { const value = getter ? getter.call(obj) : val if (newVal === value || (newVal !== newVal && value !== value)) { return } if (process.env.NODE_ENV !== 'production' && customSetter) { customSetter() } val = newVal childOb = !shallow && observe(newVal) dep.notify() /**通知相关依赖进行更新**/ } }) Vue.js 中模板编译原理?
答:将template转化成render函数
function baseCompile ( template: string, options: CompilerOptions ) { const ast = parse(template.trim(), options) // 1.将模板转化成ast语法树 if (options.optimize !== false) { // 2.优化树 optimize(ast, options) } const code = generate(ast, options) // 3.生成树 return { ast, render: code.render, staticRenderFns: code.staticRenderFns } }) const ncname = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`; const qnameCapture = `((?:${ncname}\\:)?${ncname})`; const startTagOpen = new RegExp(`^<${qnameCapture}`); // 标签开头的正则 捕获的内容是标签名 const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`); // 匹配标签结尾的 const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/; // 匹配属性的 const startTagClose = /^\s*(\/?)>/; // 匹配标签结束的 > let root; let currentParent; let stack = [] function createASTElement(tagName,attrs){ return { tag:tagName, type:1, children:[], attrs, parent:null } } function start(tagName,attrs){ let element = createASTElement(tagName,attrs); if(!root){ root = element; } currentParent = element; stack.push(element); } function chars(text){ currentParent.children.push({ type:3, text }) } function end(tagName){ const element = stack[stack.length-1]; stack.length --; currentParent = stack[stack.length-1]; if(currentParent){ element.parent = currentParent; currentParent.children.push(element) } } function parseHTML(html){ while(html){ let textEnd = html.indexOf('<'); if(textEnd == 0){ const startTagMatch = parseStartTag(); if(startTagMatch){ start(startTagMatch.tagName,startTagMatch.attrs); continue; } const endTagMatch = html.match(endTag); if(endTagMatch){ advance(endTagMatch[0].length); end(endTagMatch[1]) } } let text; if(textEnd >=0 ){ text = html.substring(0,textEnd) } if(text){ advance(text.length); chars(text); } } function advance(n) { html = html.substring(n); } function parseStartTag(){ const start = html.match(startTagOpen); if(start){ const match = { tagName:start[1], attrs:[] } advance(start[0].length); let attr,end while(!(end = html.match(startTagClose)) && (attr=html.match(attribute))){ advance(attr[0].length); match.attrs.push({name:attr[1],value:attr[3]}) } if(end){ advance(end[0].length); return match } } } } // 生成语法树 parseHTML(` hellozf
`); function gen(node){ if(node.type == 1){ return generate(node); }else{ return `_v(${JSON.stringify(node.text)})` } } function genChildren(el){ const children = el.children; if(el.children){ return `[${children.map(c=>gen(c)).join(',')}]` }else{ return false; } } function genProps(attrs){ let str = ''; for(let i = 0; i < attrs.length;i++){ let attr = attrs[i]; str+= `${attr.name}:${attr.value},`; } return `{attrs:{${str.slice(0,-1)}}}` } function generate(el){ let children = genChildren(el); let code = `_c('${el.tag}'${ el.attrs.length? `,${genProps(el.attrs)}`:'' }${ children? `,${children}`:'' })`; return code; } // 根据语法树生成新的代码 let code = generate(root); let render = `with(this){return ${code}}`; // 包装成函数 let renderFn = new Function(render); console.log(renderFn.toString()); 简述 Vue.js 中 diff 算法原理?
答:
- 1.先同级比较,在比较子节点
- 2.先判断一方有儿子一方没儿子的情况
- 3.比较都有儿子的情况
- 4.递归比较子节点
const oldCh = oldVnode.children // 老的儿子 const ch = vnode.children // 新的儿子 if (isUndef(vnode.text)) { if (isDef(oldCh) && isDef(ch)) { // 比较孩子 if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly) } else if (isDef(ch)) { // 新的儿子有 老的没有 if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '') addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue) } else if (isDef(oldCh)) { // 如果老的有新的没有 就删除 removeVnodes(oldCh, 0, oldCh.length - 1) } else if (isDef(oldVnode.text)) { // 老的有文本 新的没文本 nodeOps.setTextContent(elm, '') // 将老的清空 } } else if (oldVnode.text !== vnode.text) { // 文本不相同替换 nodeOps.setTextContent(elm, vnode.text) } function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) { let oldStartIdx = 0 let newStartIdx = 0 let oldEndIdx = oldCh.length - 1 let oldStartVnode = oldCh[0] let oldEndVnode = oldCh[oldEndIdx] let newEndIdx = newCh.length - 1 let newStartVnode = newCh[0] let newEndVnode = newCh[newEndIdx] let oldKeyToIdx, idxInOld, vnodeToMove, refElm // removeOnly is a special flag used only by // to ensure removed elements stay in correct relative positions // during leaving transitions const canMove = !removeOnly if (process.env.NODE_ENV !== 'production') { checkDuplicateKeys(newCh) } while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { if (isUndef(oldStartVnode)) { oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left } else if (isUndef(oldEndVnode)) { oldEndVnode = oldCh[--oldEndIdx] } else if (sameVnode(oldStartVnode, newStartVnode)) { patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx) oldStartVnode = oldCh[++oldStartIdx] newStartVnode = newCh[++newStartIdx] } else if (sameVnode(oldEndVnode, newEndVnode)) { patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx) oldEndVnode = oldCh[--oldEndIdx] newEndVnode = newCh[--newEndIdx] } else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx) canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm)) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] } else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx) canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] } else { if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) if (isUndef(idxInOld)) { // New element createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx) } else { vnodeToMove = oldCh[idxInOld] if (sameVnode(vnodeToMove, newStartVnode)) { patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx) oldCh[idxInOld] = undefined canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm) } else { // same key but different element. treat as new element createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx) } } newStartVnode = newCh[++newStartIdx] } } if (oldStartIdx > oldEndIdx) { refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue) } else if (newStartIdx > newEndIdx) { removeVnodes(oldCh, oldStartIdx, oldEndIdx) } } Vue.js 的v-model实现原理,及如何自定义v-model?
答:组件的v-model是value+input方法的语法糖
可以自己重新定义v-model的含义
Vue.component('el-checkbox',{ template:``, model:{ prop:'check', // 更改默认的value的名字 event:'change' // 更改默认的方法名 }, props: { check: Boolean }, }) 会将组件的v-model默认转化成value+input
const VueTemplateCompiler = require('vue-template-compiler'); const ele = VueTemplateCompiler.compile(' function transformModel (options, data: any) { const prop = (options.model && options.model.prop) || 'value' const event = (options.model && options.model.event) || 'input' ;(data.attrs || (data.attrs = {}))[prop] = data.model.value const on = data.on || (data.on = {}) const existing = on[event] const callback = data.model.callback if (isDef(existing)) { if ( Array.isArray(existing) ? existing.indexOf(callback) === -1 : existing !== callback ) { on[event] = [callback].concat(existing) } } else { on[event] = callback } } 原生的 v-model,会根据标签的不同生成不同的事件和属性
const VueTemplateCompiler = require('vue-template-compiler'); const ele = VueTemplateCompiler.compile(''); /** with(this) { return _c('input', { directives: [{ name: "model", rawName: "v-model", value: (value), expression: "value" }], domProps: { "value": (value) }, on: { "input": function ($event) { if ($event.target.composing) return; value = $event.target.value } } }) } */ 编译时:不同的标签解析出的内容不一样
if (el.component) { genComponentModel(el, value, modifiers) // component v-model doesn't need extra runtime return false } else if (tag === 'select') { genSelect(el, value, modifiers) } else if (tag === 'input' && type === 'checkbox') { genCheckboxModel(el, value, modifiers) } else if (tag === 'input' && type === 'radio') { genRadioModel(el, value, modifiers) } else if (tag === 'input' || tag === 'textarea') { genDefaultModel(el, value, modifiers) } else if (!config.isReservedTag(tag)) { genComponentModel(el, value, modifiers) // component v-model doesn't need extra runtime return false } 运行时:会对元素处理一些关于输入法的问题
inserted (el, binding, vnode, oldVnode) { if (vnode.tag === 'select') { // #6903 if (oldVnode.elm && !oldVnode.elm._vOptions) { mergeVNodeHook(vnode, 'postpatch', () => { directive.componentUpdated(el, binding, vnode) }) } else { setSelected(el, binding, vnode.context) } el._vOptions = [].map.call(el.options, getValue) } else if (vnode.tag === 'textarea' || isTextInputType(el.type)) { el._vModifiers = binding.modifiers if (!binding.modifiers.lazy) { el.addEventListener('compositionstart', onCompositionStart) el.addEventListener('compositionend', onCompositionEnd) // Safari < 10.2 & UIWebView doesn't fire compositionend when // switching focus before confirming composition choice // this also fixes the issue where some browsers e.g. iOS Chrome // fires "change" instead of "input" on autocomplete. el.addEventListener('change', onCompositionEnd) /* istanbul ignore if */ if (isIE9) { el.vmodel = true } } } } Vue.js 组件的生命周期?
答:总共分为8个阶段创建前/后,载⼊前/后,更新前/后,销毁前/后
- 创建前/后: 在 beforeCreate 阶段, vue 实例的挂载元素 el 和数据对象 data 都为undefined ,还未初始化。在 created 阶段, vue 实例的数据对象 data 有了,el还 没有
- 载⼊前/后:在 beforeMount 阶段, vue 实例的 $el 和 data 都初始化了,但还是挂载之前为虚拟的 dom 节点, data.message 还未替换。在 mounted 阶段, vue 实例挂载完成, data.message 成功渲染。
- 更新前/后:当 data 变化时,会触发 beforeUpdate 和 updated ⽅法
- 销毁前/后:在执⾏ destroy ⽅法后,对 data 的改变不会再触发周期函数,说明此时 vue 实例已经解除了事件监听以及和 dom 的绑定,但是 dom 结构依然存在
要掌握每个生命周期什么时候被调用
beforeCreate在实例初始化之后,数据观测(data observer) 之前被调用。created实例已经创建完成之后被调用。在这一步,实例已完成以下的配置:数据观测(data observer),属性和方法的运算, watch/event 事件回调。这里没有$elbeforeMount在挂载开始之前被调用:相关的 render 函数首次被调用。mountedel 被新创建的vm.$el替换,并挂载到实例上去之后调用该钩子。beforeUpdate数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁之前。updated由于数据更改导致的虚拟 DOM 重新渲染和打补丁,在这之后会调用该钩子。beforeDestroy实例销毁之前调用。在这一步,实例仍然完全可用。destroyedVue实例销毁后调用。调用后,Vue实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。 该钩子在服务器端渲染期间不被调用。
要掌握每个生命周期内部可以做什么事
created实例已经创建完成,因为它是最早触发的原因可以进行一些数据,资源的请求。mounted实例已经挂载完成,可以进行一些DOM操作beforeUpdate可以在这个钩子中进一步地更改状态,这不会触发附加的重渲染过程。updated可以执行依赖于 DOM 的操作。然而在大多数情况下,你应该避免在此期间更改状态,因为这可能会导致更新无限循环。 该钩子在服务器端渲染期间不被调用。destroyed可以执行一些优化操作,清空定时器,解除绑定事件
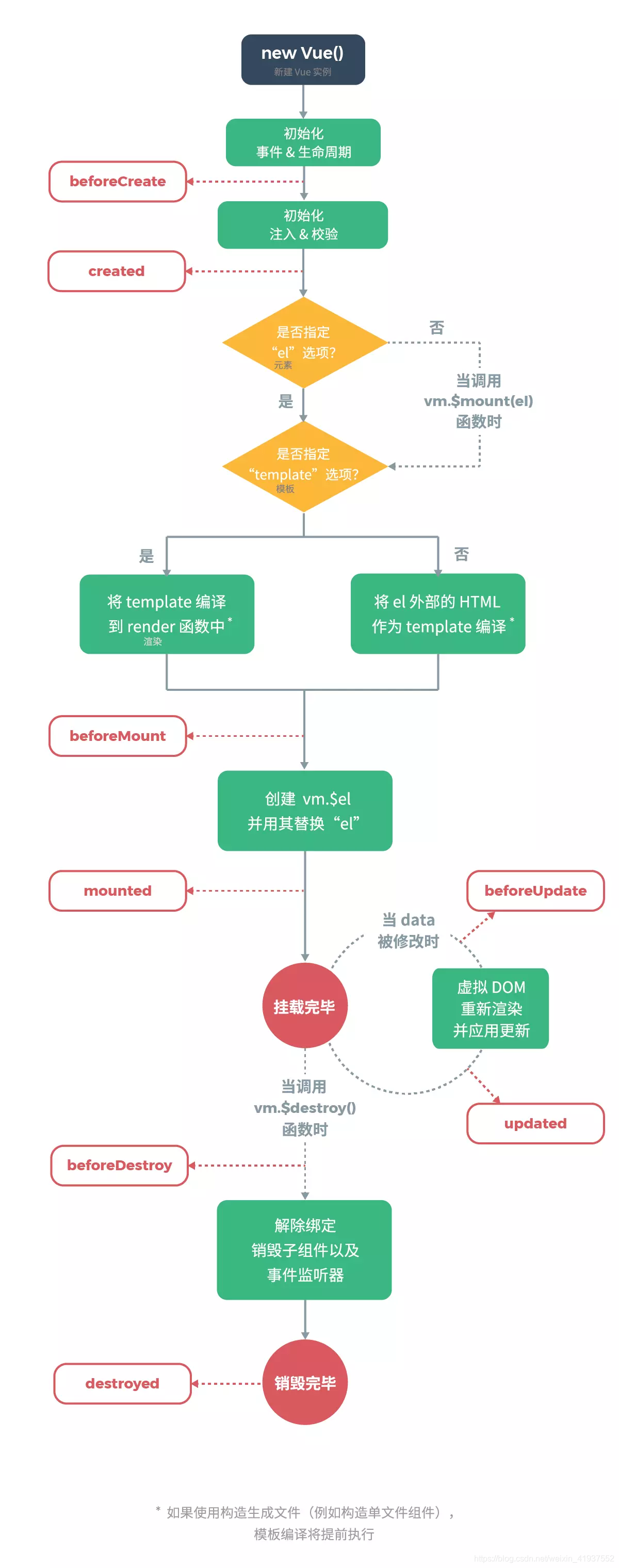
什么是vue⽣命周期?
答: Vue 实例从创建到销毁的过程,就是⽣命周期。从开始创建、初始化数据、编译模板、挂载Dom→渲染、更新→渲染、销毁等⼀系列过程,称之为 Vue 的⽣命周期。
vue⽣命周期的作⽤是什么?
答:它的⽣命周期中有多个事件钩⼦,让我们在控制整个Vue实例的过程时更容易形成好的 逻辑。
vue⽣命周期总共有⼏个阶段?
答:它可以总共分为 8 个阶段:创建前/后、载⼊前/后、更新前/后、销毁前/销毁后。
第⼀次页⾯加载会触发哪⼏个钩⼦?
答:会触发下⾯这⼏个 beforeCreate 、 created 、 beforeMount 、 mounted 。
DOM 渲染在哪个周期中就已经完成?
答: DOM 渲染在 mounted 中就已经完成了
描述组件渲染和更新过程?
答:渲染组件时,会通过Vue.extend方法构建子组件的构造函数,并进行实例化。最终手动调用$mount()进行挂载。更新组件时会进行patchVnode流程.核心就是diff算法

Vue.js 组件如何通信以及有哪些方式?
答:
- 父子间通信 父->子通过
props、子-> 父$on、$emit - 获取父子组件实例的方式
$parent、$children - 在父组件中提供数据子组件进行消费
Provide、inject Ref获取实例的方式调用组件的属性或者方法Event Bus实现跨组件通信Vuex状态管理实现通信
1. ⽗⼦通信
⽗组件通过 props 传递数据给⼦组件,⼦组件通过 emit 发送事件传递数据给⽗组件, 这两种⽅式是最常⽤的⽗⼦通信实现办法。
这种⽗⼦通信⽅式也就是典型的单向数据流,⽗组件通过 props 传递数据,⼦组件不能 直接修改 props ,⽽是必须通过发送事件的⽅式告知⽗组件修改数据。
另外这两种⽅式还可以使⽤语法糖 v-model 来直接实现,因为 v-model 默认会解析成 名为 value 的 prop 和名为 input 的事件。这种语法糖的⽅式是典型的双向绑定, 常⽤于 UI 控件上,但是究其根本,还是通过事件的⽅法让⽗组件修改数据。
当然我们还可以通过访问 $parent 或者 $children 对象来访问组件实例中的⽅法和数 据。
另外如果你使⽤ Vue 2.3 及以上版本的话还可以使⽤ $listeners 和 .sync 这两个属 性。
$listeners 属性会将⽗组件中的 (不含 .native 修饰器的) v-on 事件监听器传递给 ⼦组件,⼦组件可以通过访问 $listeners 来⾃定义监听器。
.sync 属性是个语法糖,可以很简单的实现⼦组件与⽗组件通信
2. 兄弟组件通信
对于这种情况可以通过查找⽗组件中的⼦组件实现,也就是 this.$parent.$children ,在 $children 中可以通过组件 name 查询 到需要的组件实例,然后进⾏通信。
3. 跨多层次组件通信
对于这种情况可以使⽤ Vue 2.2 新增的 API provide / inject ,虽然⽂ 档中不推荐直接使⽤在业务中,但是如果⽤得好的话还是很有⽤的。
假设有⽗组件 A ,然后有⼀个跨多层级的⼦组件 B
// ⽗组件 Aexport default {provide: {data: 1}}// ⼦组件 Bexport default {inject: ['data'],mounted() {// ⽆论跨⼏层都能获得⽗组件的 data 属性console.log(this.data) // => 1}} 终极办法解决⼀切通信问题
只要你不怕麻烦,可以使⽤ Vuex 或者 Event Bus 解决上述所有的通信情况。
为何 Vue.js 采用异步渲染?
答:因为如果不采用异步更新,那么每次更新数据都会对当前组件进行重新渲染.
所以为了性能考虑。Vue会在本轮数据更新后,再去异步更新视图!
有点类似节流的原理
update () { /* istanbul ignore else */ if (this.lazy) { this.dirty = true } else if (this.sync) { this.run() } else { queueWatcher(this); // 当数据发生变化时会将watcher放到一个队列中批量更新 } } export function queueWatcher (watcher: Watcher) { const id = watcher.id // 会对相同的watcher进行过滤 if (has[id] == null) { has[id] = true if (!flushing) { queue.push(watcher) } else { let i = queue.length - 1 while (i > index && queue[i].id > watcher.id) { i-- } queue.splice(i + 1, 0, watcher) } // queue the flush if (!waiting) { waiting = true if (process.env.NODE_ENV !== 'production' && !config.async) { flushSchedulerQueue() return } nextTick(flushSchedulerQueue) // 调用nextTick方法 批量的进行更新 } } } Vue.js 中 v-if 和 v-show 的区别?
答:
v-if如果条件不成立不会渲染当前指令所在节点的dom元素v-show只是切换当前dom的显示或者隐藏
v-show 只是在 display: none 和 display: block 之间切换。⽆论初始条件是什么 都会被渲染出来,后⾯只需要切换 CSS , DOM 还是⼀直保留着的。所以总的来说 v- show 在初始渲染时有更⾼的开销,但是切换开销很⼩,更适合于频繁切换的场景。
v-if 的话就得说到 Vue 底层的编译了。当属性初始为 false 时,组件就不会被渲 染,直到条件为 true ,并且切换条件时会触发销毁/挂载组件,所以总的来说在切换时开 销更⾼,更适合不经常切换的场景。
并且基于 v-if 的这种惰性渲染机制,可以在必要的时候才去渲染组件,减少整个⻚⾯的 初始渲染开销。
总结: v-if 按照条件是否渲染, v-show 是 display 的 block 或 none ;
const VueTemplateCompiler = require('vue-template-compiler'); let r1 = VueTemplateCompiler.compile(` hello `); /** with(this) { return (true) ? _c('div', _l((3), function (i) { return _c('span', [_v("hello")]) }), 0) : _e() } */ const VueTemplateCompiler = require('vue-template-compiler'); let r2 = VueTemplateCompiler.compile(` `); /** with(this) { return _c('div', { directives: [{ name: "show", rawName: "v-show", value: (true), expression: "true" }] }) } */ // v-show 操作的是样式 定义在platforms/web/runtime/directives/show.js bind (el: any, { value }: VNodeDirective, vnode: VNodeWithData) { vnode = locateNode(vnode) const transition = vnode.data && vnode.data.transition const originalDisplay = el.__vOriginalDisplay = el.style.display === 'none' ? '' : el.style.display if (value && transition) { vnode.data.show = true enter(vnode, () => { el.style.display = originalDisplay }) } else { el.style.display = value ? originalDisplay : 'none' } } Vue.js中为什么 v-for 和 v-if 不能连用?
答:v-for会比v-if的优先级高一些,如果连用的话会把v-if给每个元素都添加一下,会造成性能问题
const VueTemplateCompiler = require('vue-template-compiler'); let r1 = VueTemplateCompiler.compile(` hello `); /** with(this) { return _l((3), function (i) { return (false) ? _c('div', [_v("hello")]) : _e() }) } */ console.log(r1.render); Vue.js 中实现 hash路由和history路由?
答:
onhashchange-
history.pushState -
hash 模式:在浏览器中符号 “#” ,#以及#后⾯的字符称之为 hash ,⽤ window.location.hash 读取。特点: hash 虽然在 URL 中,但不被包括在 HTTP 请求中;⽤来指导浏览器动作,对服务端安全⽆⽤, hash 不会重加载⻚⾯。
-
history 模式:h istory 采⽤ HTML5 的新特性;且提供了两个新⽅法:pushState() , replaceState() 可以对浏览器历史记录栈进⾏修改,以及 popState 事件的监听到状态变更
Vue.js 的 action 和 mutation 区别?
答:
mutation是同步更新数据(内部会进行是否为异步方式更新数据的检测)action异步操作,可以获取数据后调佣mutation提交最终数据
Vue.js 和 react 区别?
答:相同点
都⽀持 ssr ,都有 vdom ,组件化开发,实现 webComponents 规范,数据驱 动等
不同点
vue 是双向数据流(当然为了实现单数据流⽅便管理组件状态, vuex 便出现了), react 是单向数据流。 vue 的 vdom 是追踪每个组件的依赖关系,不会渲染整个组件树, react 每当应该状态被改变时,全部⼦组件都会 re-render

React.js 面试题
React ⽣命周期函数?
答:在 V16 版本中引⼊了 Fiber 机制。这个机制⼀定程度上的影响了部分⽣命 周期的调⽤,并且也引⼊了新的 2 个 API 来解决问题
在之前的版本中,如果你拥有⼀个很复杂的复合组件,然后改动了最上层组件 的 state ,那么调⽤栈可能会很调⽤栈过,再加上中间进⾏了复杂的操作,就可能导致⻓时间阻塞主线程,带来不好的 ⽤户体验。 Fiber 就是为了解决该问题⽽⽣Fiber 本质上是⼀个虚拟的堆栈帧,新的调度器会按照优先级⾃由调度这些帧,从⽽将 之前的同步渲染改成了异步渲染,在不影响体验的情况下去分段计算更新对于如何区别优先级, React 有⾃⼰的⼀套逻辑。对于动画这种实时性很⾼的东⻄,也 就是 16 ms 必须渲染⼀次保证不卡顿的情况下, React 会每 16 ms (以内) 暂停⼀ 下更新,返回来继续渲染动画,对于异步渲染,现在渲染有两个阶段: reconciliation 和 commit 。前者过程是可以 打断的,后者不能暂停,会⼀直更新界⾯直到完成。
初始化阶段
- getDefaultProps :获取实例的默认属性
- getInitialState :获取每个实例的初始化状态
- componentWillMount :组件即将被装载、渲染到⻚⾯上
- render :组件在这⾥⽣成虚拟的 DOM 节点
- omponentDidMount :组件真正在被装载之后
运⾏中状态
- componentWillReceiveProps :组件将要接收到属性的时候调⽤
- shouldComponentUpdate :组件接受到新属性或者新状态的时候(可以返回false,接收数
- 据后不更新,阻⽌ render 调⽤,后⾯的函数不会被继续执⾏了)
- componentWillUpdate :组件即将更新不能修改属性和状态
- render :组件重新描绘
- componentDidUpdate :组件已经更新
销毁阶段
- componentWillUnmount :组件即将销毁
因为 Reconciliation 阶段是可以被打断的,所以 Reconciliation 阶段 会执⾏的⽣命周期函数就可能会出现调⽤多次的情况,从⽽引起 Bug 。由此 对于 Reconciliation 阶段调⽤的⼏个函数,除了 shouldComponentUpdate 以外,其他都应该避免去使⽤,并且 V16 中也 引⼊了新的 API 来解决这个问题。
getDerivedStateFromProps ⽤于替换 componentWillReceiveProps , 该函数会在初始化和 update 时被调⽤
React 中 keys 的作⽤是什么?
答:Keys 是 React ⽤于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识
在开发过程中,我们需要保证某个元素的 key 在其同级元素中具有唯⼀性。在 React Diff 算法中 React 会借助元素的 Key 值来判断该元素是新近创建的还是被移动⽽来 的元素,从⽽减少不必要的元素重渲染。此外,React 还需要借助 Key 值来判断元素与 本地状态的关联关系,因此我们绝不可忽视转换函数中 Key 的重要性
React 中 refs 的作⽤是什么?
答:
- Refs 是 React 提供给我们的安全访问 DOM 元素或者某个组件实例的句柄
- 可以为元素添加 ref 属性然后在回调函数中接受该元素在 DOM 树中的句柄,该值会作为回调函数的第⼀个参数返回
React Native相对于原生的ios和Android有哪些优势?
答:
- 1.性能媲美原生APP
- 2.使用JavaScript编码,只要学习这一种语言
- 3.绝大部分代码安卓和IOS都能共用
- 4.组件式开发,代码重用性很高
- 5.跟编写网页一般,修改代码后即可自动刷新,不需要慢慢编译,节省很多编译等待时间
- 6.支持APP热更新,更新无需重新安装APP
缺点:
- 内存占用相对较高
- 版本还不稳定,一直在更新,现在还没有推出稳定的1.0版本
props和state相同点和不同点?
答:1.不管是props还是state的改变,都会引发render的重新渲染。
2.都能由自身组件的相应初始化函数设定初始值。
不同点
1.初始值来源:state的初始值来自于自身的getInitalState(constructor)函数;props来自于父组件或者自身getDefaultProps(若key相同前者可覆盖后者)。
2.修改方式:state只能在自身组件中setState,不能由父组件修改;props只能由父组件修改,不能在自身组件修改。
3.对子组件:props是一个父组件传递给子组件的数据流,这个数据流可以一直传递到子孙组件;state代表的是一个组件内部自身的状态,只能在自身组件中存在。
简述flux 思想?答:Flux 的最⼤特点,就是数据的”单向流动”。
- ⽤户访问 View
- View 发出⽤户的 Action
- Dispatcher 收到 Action ,要求 Store 进⾏相应的更新
- Store 更新后,发出⼀个 “change” 事件
- View 收到 “change” 事件后,更新页⾯
说说你⽤react有什么坑点?
答:
- JSX做表达式判断时候,需要强转为boolean类型
如果不使⽤ !!b 进⾏强转数据类型,会在页⾯⾥⾯输出 0 。
render() {const b = 0;return <div>{!!b && <div>这是⼀段⽂本</div>}</div>}
-
尽量不要在 componentWillReviceProps ⾥使⽤ setState,如果⼀定要使⽤,那么需要判 断结束条件,不然会出现⽆限重渲染,导致页⾯崩溃
-
给组件添加ref时候,尽量不要使⽤匿名函数,因为当组件更新的时候,匿名函数会被当做 新的prop处理,让ref属性接受到新函数的时候,react内部会先清空ref,也就是会以null为回 调参数先执⾏⼀次ref这个props,然后在以该组件的实例执⾏⼀次ref,所以⽤匿名函数做ref 的时候,有的时候去ref赋值后的属性会取到null
-
遍历⼦节点的时候,不要⽤ index 作为组件的 key 进⾏传⼊
React 性能优化⽅案?
答:
- 重写 shouldComponentUpdate 来避免不必要的dom操作
- 使⽤ production 版本的 react.js
- 使⽤ key 来帮助 React 识别列表中所有⼦组件的最⼩变化
在 shouldComponentUpdate 函数中我们可以通过返回布尔值来决定当前组件是否需要更 新。这层代码逻辑可以是简单地浅⽐较⼀下当前 state 和之前的 state 是否相同,也 可以是判断某个值更新了才触发组件更新。⼀般来说不推荐完整地对⽐当前 state 和之 前的 state 是否相同,因为组件更新触发可能会很频繁,这样的完整对⽐性能开销会有 点⼤,可能会造成得不偿失的情况
当然如果真的想完整对⽐当前 state 和之前的 state 是否相同,并且不影响性能也是 ⾏得通的,可以通过 immutable 或者 immer 这些库来⽣成不可变对象。这类库对于操 作⼤规模的数据来说会提升不错的性能,并且⼀旦改变数据就会⽣成⼀个新的对象,对⽐ 前后 state 是否⼀致也就⽅便多了,同时也很推荐阅读下 immer 的源码实现
另外如果只是单纯的浅⽐较⼀下,可以直接使⽤ PureComponent ,底层就是实现了浅⽐较 state
class Test extends React.PureComponent { render() { return ( PureComponent ) } } 这时候你可能会考虑到函数组件就不能使⽤这种⽅式了,如果你使⽤16.6.0 之后的版本的话,可以使⽤ React.memo 来实现相同的功能
const Test = React.memo(() => (PureComponent))
通过这种⽅式我们就可以既实现了 shouldComponentUpdate 的浅⽐较,⼜能够使⽤函数组件
React 监控?
答:
前端监控⼀般分为三种,分别为⻚⾯埋点、性能监控以及异常监控。
这⼀章节我们将来学习这些监控相关的内容,但是基本不会涉及到代码,只是让⼤家了解下前 端监控该⽤什么⽅式实现。毕竟⼤部分公司都只是使⽤到了第三⽅的监控⼯具,⽽不是选择⾃ ⼰造轮⼦
1 页⾯埋点
页⾯埋点应该是⼤家最常写的监控了,⼀般起码会监控以下⼏个数据:
- PV / UV
- 停留时⻓
- 流量来源
- ⽤户交互
对于这⼏类统计,⼀般的实现思路⼤致可以分为两种,分别为⼿写埋点和⽆埋 点的⽅式。
相信第⼀种⽅式也是⼤家最常⽤的⽅式,可以⾃主选择需要监控的数据然后在相应的地⽅写⼊ 代码。这种⽅式的灵活性很⼤,但是唯⼀的缺点就是⼯作量较⼤,每个需要监控的地⽅都得插 ⼊代码。
另⼀种⽆埋点的⽅式基本不需要开发者⼿写埋点了,⽽是统计所有的事件并且定时上报。这种 ⽅式虽然没有前⼀种⽅式繁琐了,但是因为统计的是所有事件,所以还需要后期过滤出需要的 数据。
2 性能监控
性能监控可以很好的帮助开发者了解在各种真实环境下,⻚⾯的性能情况是如何的。
对于性能监控来说,我们可以直接使⽤浏览器⾃带的 Performance API 来实现这个功 能。
对于性能监控来说,其实我们只需要调⽤
performance.getEntriesByType(‘navigation’) 这⾏代码就⾏了。对,你没看错,⼀ ⾏代码我们就可以获得⻚⾯中各种详细的性能相关信息
我们可以发现这⾏代码返回了⼀个数组,内部包含了相当多的信息,从数据开 始在⽹络中传输到⻚⾯加载完成都提供了相应的数据
3 异常监控
对于异常监控来说,以下两种监控是必不可少的,分别是代码报错以及接⼝异常上报。 对于代码运⾏错误,通常的办法是使⽤ window.onerror 拦截报错。该⽅法能拦截到⼤ 部分的详细报错信息,但是也有例外
-
对于跨域的代码运⾏错误会显示 Script error . 对于这种情况我们需要给 script 标签 添加 crossorigin 属性
-
对于某些浏览器可能不会显示调⽤栈信息,这种情况可以通过 arguments.callee.caller 来做栈递归
对于异步代码来说,可以使⽤ catch 的⽅式捕获错误。⽐如 Promise 可以直接使⽤ catch 函数, async await 可以使⽤ try catch
但是要注意线上运⾏的代码都是压缩过的,需要在打包时⽣成 sourceMap ⽂件便于 debug
对于捕获的错误需要上传给服务器,通常可以通过 img 标签的 src 发起⼀个请求。
另外接⼝异常就相对来说简单了,可以列举出出错的状态码。⼀旦出现此类的状态码就可 以⽴即上报出错。接⼝异常上报可以让开发⼈员迅速知道有哪些接⼝出现了⼤⾯积的报 错,以便迅速修复问题。
React.js 通信?
答:1. ⽗⼦通信
⽗组件通过 props 传递数据给⼦组件,⼦组件通过调⽤⽗组件传来的函数传递数据给⽗ 组件,这两种⽅式是最常⽤的⽗⼦通信实现办法。
这种⽗⼦通信⽅式也就是典型的单向数据流,⽗组件通过 props 传递数据,⼦组件不能 直接修改 props , ⽽是必须通过调⽤⽗组件函数的⽅式告知⽗组件修改数据。
2. 兄弟组件通信
对于这种情况可以通过共同的⽗组件来管理状态和事件函数。⽐如说其中⼀个 兄弟组件调⽤⽗组件传递过来的事件函数修改⽗组件中的状态,然后⽗组件将 状态传递给另⼀个兄弟组件
3. 跨多层次组件通信
如果你使⽤ 16.3 以上版本的话,对于这种情况可以使⽤ Context API
// 创建 Context,可以在开始就传⼊值const StateContext = React.createContext()class Parent extends React.Component {render () {return (// value 就是传⼊ Context 中的值 )}}class Child extends React.Component {render () {return ( // 取出值{context => (name is { context })} );}} 4. 任意组件
这种⽅式可以通过 Redux 或者 Event Bus 解决,另外如果你不怕麻烦的 话,可以使⽤这种⽅式解决上述所有的通信情况。
React 事件机制?
答:React 其实⾃⼰实现了⼀套事件机制,⾸先我们考虑⼀下以下代码
const Test = ({ list, handleClick }) => ({ list.map((item, index) => ( <span onClick={handleClick} key={index}>{index}</span> )) })
以上类似代码想必⼤家经常会写到,但是你是否考虑过点击事件是否绑定在了每⼀个标签 上?事实当然不是, JSX 上写的事件并没有绑定在对应的真实 DOM 上,⽽是通过事件 代理的⽅式,将所有的事件都统⼀绑定在了 document 上。这样的⽅式不仅减少了内存消 耗,还能在组件挂载销毁时统⼀订阅和移除事件。
另外冒泡到 document 上的事件也不是原⽣浏览器事件,⽽是 React ⾃⼰实现的合成 事件( SyntheticEvent )。因此我们如果不想要事件冒泡的话,调⽤ event.stopPropagation 是⽆效的,⽽应该调⽤ event.preventDefault
那么实现合成事件的⽬的是什么呢?总的来说在我看来好处有两点,分别是:
-
合成事件⾸先抹平了浏览器之间的兼容问题,另外这是⼀个跨浏览器原⽣事件包装器,赋 予了跨浏览器开发的能⼒
-
对于原⽣浏览器事件来说,浏览器会给监听器创建⼀个事件对象。如果你有很多的事件监 听,那么就需要分配很多的事件对象,造成⾼额的内存分配问题。但是对于合成事件来 说,有⼀个事件池专⻔来管理它们的创建和销毁,当事件需要被使⽤时,就会从池⼦中复 ⽤对象,事件回调结束后,就会销毁事件对象上的属性,从⽽便于下次复⽤事件对象。

工具面试题
git 与 svn 的区别在哪里?
答:git 和 svn 最大的区别在于 git 是分布式的,而 svn 是集中式的。因此我们不能再离线的情况下使用 svn。如果服务器 出现问题,我们就没有办法使用 svn 来提交我们的代码。
svn 中的分支是整个版本库的复制的一份完整目录,而 git 的分支是指针指向某次提交,因此 git 的分支创建更加开销更小 并且分支上的变化不会影响到其他人。svn 的分支变化会影响到所有的人。
svn 的指令相对于 git 来说要简单一些,比 git 更容易上手。
经常使用的 git 命令?
答:
git init // 新建 git 代码库 git add // 添加指定文件到暂存区 git rm // 删除工作区文件,并且将这次删除放入暂存区 git commit -m [message] // 提交暂存区到仓库区 git branch // 列出所有分支 git checkout -b [branch] // 新建一个分支,并切换到该分支 git status // 显示有变更的文件
git pull 和 git fetch 的区别?
答:git fetch 只是将远程仓库的变化下载下来,并没有和本地分支合并。
git pull 会将远程仓库的变化下载下来,并和当前分支合并。
git rebase 和 git merge 的区别?
答:git merge 和 git rebase 都是用于分支合并,关键在 commit 记录的处理上不同。
git merge 会新建一个新的 commit 对象,然后两个分支以前的 commit 记录都指向这个新 commit 记录。这种方法会 保留之前每个分支的 commit 历史。
git rebase 会先找到两个分支的第一个共同的 commit 祖先记录,然后将提取当前分支这之后的所有 commit 记录,然后 将这个 commit 记录添加到目标分支的最新提交后面。经过这个合并后,两个分支合并后的 commit 记录就变为了线性的记 录了。
算法面试题
JavaScript 如何求数组的最大值和最小值?
答:
var arr = [6, 4, 1, 8, 2, 11, 23]; console.log(Math.max.apply(null, arr))
如何查找一篇英文文章中出现频率最高的单词?
答:
function findMostWord(article) { // 合法性判断 if (!article) return; // 参数处理 article = article.trim().toLowerCase(); let wordList = article.match(/[a-z]+/g), visited = [], maxNum = 0, maxWord = ""; article = " " + wordList.join(" ") + " "; // 遍历判断单词出现次数 wordList.forEach(function (item) { if (visited.indexOf(item) < 0) { let word = new RegExp(" " + item + " ", "g"), num = article.match(word).length; if (num > maxNum) { maxNum = num; maxWord = item; } } }); return maxWord + " " + maxNum; } JavaScript 冒泡排序?
答:冒泡排序的基本思想是,对相邻的元素进行两两比较,顺序相反则进行交换,这样,每一趟会将最小或最大的元素“浮”到顶端,最终达到完全有序。
代码实现:
function bubbleSort(arr) { if (!Array.isArray(arr) || arr.length <= 1) return; let lastIndex = arr.length - 1; while (lastIndex > 0) { // 当最后一个交换的元素为第一个时,说明后面全部排序完毕 let flag = true, k = lastIndex; for (let j = 0; j < k; j++) { if (arr[j] > arr[j + 1]) { flag = false; lastIndex = j; // 设置最后一次交换元素的位置 [arr[j], arr[j+1]] = [arr[j+1], arr[j]]; } } if (flag) break; } } 冒泡排序有两种优化方式。
一种是外层循环的优化,我们可以记录当前循环中是否发生了交换,如果没有发生交换,则说明该序列已经为有序序列了。 因此我们不需要再执行之后的外层循环,此时可以直接结束。
一种是内层循环的优化,我们可以记录当前循环中最后一次元素交换的位置,该位置以后的序列都是已排好的序列,因此下 一轮循环中无需再去比较。
优化后的冒泡排序,当排序序列为已排序序列时,为最好的时间复杂度为 O(n)。
冒泡排序的平均时间复杂度为 O(n²) ,最坏时间复杂度为 O(n²) ,空间复杂度为 O(1) ,是稳定排序。
JavaScript 选择排序?
答:选择排序的基本思想为每一趟从待排序的数据元素中选择最小(或最大)的一个元素作为首元素,直到所有元素排完为止。
在算法实现时,每一趟确定最小元素的时候会通过不断地比较交换来使得首位置为当前最小,交换是个比较耗时的操作。其实 我们很容易发现,在还未完全确定当前最小元素之前,这些交换都是无意义的。我们可以通过设置一个变量 min,每一次比较 仅存储较小元素的数组下标,当轮循环结束之后,那这个变量存储的就是当前最小元素的下标,此时再执行交换操作即可。
代码实现:
function selectSort(array) { let length = array.length; // 如果不是数组或者数组长度小于等于1,直接返回,不需要排序 if (!Array.isArray(array) || length <= 1) return; for (let i = 0; i < length - 1; i++) { let minIndex = i; // 设置当前循环最小元素索引 for (let j = i + 1; j < length; j++) { // 如果当前元素比最小元素索引,则更新最小元素索引 if (array[minIndex] > array[j]) { minIndex = j; } } // 交换最小元素到当前位置 // [array[i], array[minIndex]] = [array[minIndex], array[i]]; swap(array, i, minIndex); } return array; } // 交换数组中两个元素的位置 function swap(array, left, right) { var temp = array[left]; array[left] = array[right]; array[right] = temp; } 选择排序不管初始序列是否有序,时间复杂度都为 O(n²)。
选择排序的平均时间复杂度为 O(n²) ,最坏时间复杂度为 O(n²) ,空间复杂度为 O(1) ,不是稳定排序。
JavaScript 插入排序?
答:直接插入排序基本思想是每一步将一个待排序的记录,插入到前面已经排好序的有序序列中去,直到插完所有元素为止。
插入排序核心–扑克牌思想: 就想着自己在打扑克牌,接起来一张,放哪里无所谓,再接起来一张,比第一张小,放左边, 继续接,可能是中间数,就插在中间….依次
代码实现:
function insertSort(array) { let length = array.length; // 如果不是数组或者数组长度小于等于1,直接返回,不需要排序 if (!Array.isArray(array) || length <= 1) return; // 循环从 1 开始,0 位置为默认的已排序的序列 for (let i = 1; i < length; i++) { let temp = array[i]; // 保存当前需要排序的元素 let j = i; // 在当前已排序序列中比较,如果比需要排序的元素大,就依次往后移动位置 while (j -1 >= 0 && array[j - 1] > temp) { array[j] = array[j - 1]; j--; } // 将找到的位置插入元素 array[j] = temp; } return array; } 当排序序列为已排序序列时,为最好的时间复杂度 O(n)。
插入排序的平均时间复杂度为 O(n²) ,最坏时间复杂度为 O(n²) ,空间复杂度为 O(1) ,是稳定排序。
JavaScript 希尔排序?
答:希尔排序的基本思想是把数组按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的元 素越来越多,当增量减至1时,整个数组恰被分成一组,算法便终止。
function hillSort(array) { let length = array.length; // 如果不是数组或者数组长度小于等于1,直接返回,不需要排序 if (!Array.isArray(array) || length <= 1) return; // 第一层确定增量的大小,每次增量的大小减半 for (let gap = parseInt(length >> 1); gap >= 1; gap = parseInt(gap >> 1)) { // 对每个分组使用插入排序,相当于将插入排序的1换成了 n for (let i = gap; i < length; i++) { let temp = array[i]; let j = i; while (j - gap >= 0 && array[j - gap] > temp) { array[j] = array[j - gap]; j -= gap; } array[j] = temp; } } return array; } 希尔排序是利用了插入排序对于已排序序列排序效果最好的特点,在一开始序列为无序序列时,将序列分为多个小的分组进行 基数排序,由于排序基数小,每次基数排序的效果较好,然后在逐步增大增量,将分组的大小增大,由于每一次都是基于上一 次排序后的结果,所以每一次都可以看做是一个基本排序的序列,所以能够最大化插入排序的优点。
简单来说就是,由于开始时每组只有很少整数,所以排序很快。之后每组含有的整数越来越多,但是由于这些数也越来越有序, 所以排序速度也很快。
希尔排序的时间复杂度根据选择的增量序列不同而不同,但总的来说时间复杂度是小于 O(n^2) 的。
插入排序是一个稳定排序,但是在希尔排序中,由于相同的元素可能在不同的分组中,所以可能会造成相同元素位置的变化, 所以希尔排序是一个不稳定的排序。
希尔排序的平均时间复杂度为 O(nlogn) ,最坏时间复杂度为 O(n^s) ,空间复杂度为 O(1) ,不是稳定排序。
有一座高度是10级台阶的楼梯,从下往上走,每跨一步只能向上1级或者2级台阶。要求用程序来求出一共有多少种走法?
答:由分析可知,假设我们只差最后一步就能走上第10级阶梯,这个时候一共有两种情况,因为每一步只允许走1级或2级阶梯, 因此分别为从8级阶梯和从9九级阶梯走上去的情况。因此从0到10级阶梯的走法数量就等于从0到9级阶梯的走法数量加上 从0到8级阶梯的走法数量。依次类推,我们可以得到一个递归关系,递归结束的标志为从0到1级阶梯的走法数量和从0到 2级阶梯的走法数量。
function getClimbingWays(n) { if (n < 1) { return 0; } if (n === 1) { return 1; } if (n === 2) { return 2; } return getClimbingWays(n - 1) + getClimbingWays(n - 2); }

综合面试题
谈⼀谈let与var的区别?
答:
- let 命令不存在变量提升,如果在 let 前使⽤,会导致报错
- 如果块区中存在 let 和 const 命令,就会形成封闭作⽤域
- 不允许重复声明,因此,不能在函数内部重新声明参数
如何通过JS判断⼀个数组?
答:instanceof ⽅法
instanceof 运算符是⽤来测试⼀个对象是否在其原型链原型构造函数的属性
var arr = [];arr instanceof Array; // true
constructor ⽅法
constructor 属性返回对创建此对象的数组函数的引⽤,就是返回对象相对应的构造 函数
var arr = [];arr.constructor == Array; //true
最简单的⽅法
这种写法,是 jQuery 正在使⽤的
Object.prototype.toString.call(value) == '[object Array]' // 利⽤这个⽅法,可以写⼀个返回数据类型的⽅法 var isType = function (obj) { return Object.prototype.toString.call(obj).slice(8,-1); } ES5 新增⽅法 isArray()
var a = new Array(123);var b = new Date();console.log(Array.isArray(a)); //trueconsole.log(Array.isArray(b)); //false
项⽬做过哪些性能优化?
答:
- 减少 HTTP 请求数
- 减少 DNS 查询
- 使⽤ CDN
- 避免重定向
- 图⽚懒加载
- 减少 DOM 元素数量
- 减少 DOM 操作
- 使⽤外部 JavaScript 和 CSS
- 压缩 JavaScript 、 CSS 、字体、图⽚等
- 优化 CSS Sprite
- 使⽤ iconfont
- 字体裁剪
- 多域名分发划分内容到不同域名
- 尽量减少 iframe 使⽤
- 避免图⽚ src 为空
- 把样式表放在 link 中
- 把 JavaScript 放在页⾯底部
浏览器缓存?
答:浏览器缓存分为强缓存和协商缓存。当客户端请求某个资源时,获取缓存的流 程如下
先根据这个资源的⼀些 http header 判断它是否命中强缓存,如果命中,则直接从本地 获取缓存资源,不会发请求到服务器;
当强缓存没有命中时,客户端会发送请求到服务器,服务器通过另⼀些 request header 验证这个资源是否命中协商缓存,称为 http 再验证,如果命中,服务器将请求返回,但 不返回资源,⽽是告诉客户端直接从缓存中获取,客户端收到返回后就会从缓存中获取资 源;
强缓存和协商缓存共同之处在于,如果命中缓存,服务器都不会返回资源; 区别是,强缓 存不对发送请求到服务器,但协商缓存会。
当协商缓存也没命中时,服务器就会将资源发送回客户端。
当 ctrl+f5 强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存;
当 f5 刷新网页时,跳过强缓存,但是会检查协商缓存;
强缓存
Expires (该字段是 http1.0 时的规范,值为⼀个绝对时间的 GMT 格式的时间字符 串,代表缓存资源的过期时间)
Cache-Control:max-age (该字段是 http1.1 的规范,强缓存利⽤其 max-age 值来 判断缓存资源的最⼤⽣命周期,它的值单位为秒)
协商缓存
Last-Modified (值为资源最后更新时间,随服务器response返回)
If-Modified-Since (通过⽐较两个时间来判断资源在两次请求期间是否有过修改,如 果没有修改,则命中协商缓存)
ETag (表示资源内容的唯⼀标识,随服务器 response 返回)
If-None-Match (服务器通过⽐较请求头部的 If-None-Match 与当前资源的 ETag 是 否⼀致来判断资源是否在两次请求之间有过修改,如果没有修改,则命中协商缓存
前端需要注意哪些SEO?
答:
- 合理的 title 、 description 、 keywords :搜索对着三项的权重逐个减⼩, title
- 值强调重点即可,重要关键词出现不要超过2次,⽽且要靠前,不同⻚⾯ title 要有所不
- 同; description 把⻚⾯内容⾼度概括,⻓度合适,不可过分堆砌关键词,不同⻚⾯
- description 有所不同; keywords 列举出重要关键词即可
- 语义化的 HTML 代码,符合W3C规范:语义化代码让搜索引擎容易理解⽹⻚
- 重要内容 HTML 代码放在最前:搜索引擎抓取 HTML 顺序是从上到下,有的搜索引擎对抓
- 取⻓度有限制,保证重要内容⼀定会被抓取
- 重要内容不要⽤ js 输出:爬⾍不会执⾏js获取内容
- 少⽤ iframe :搜索引擎不会抓取 iframe 中的内容
- ⾮装饰性图⽚必须加 alt
- 提⾼⽹站速度:⽹站速度是搜索引擎排序的⼀个重要指标
浏览器渲染原理?
答:1. 浏览器接收到 HTML ⽂件并转换为 DOM 树
当我们打开⼀个⽹⻚时,浏览器都会去请求对应的 HTML ⽂件。虽然平时我 们写代码时都会分为 JS 、 CSS 、 HTML ⽂件,也就是字符串,但是计算机 硬件是不理解这些字符串的,所以在⽹络中传输的内容其实都是 0 和 1 这些字节数据。当浏览器接收到这些字节数据以后,它会将这些字节数据转换为 字符串,也就是我们写的代码。
当数据转换为字符串以后,浏览器会先将这些字符串通过词法分析转换为标记 ( token ),这⼀过程在词法分析中叫做标记化( tokenization )
那么什么是标记呢?这其实属于编译原理这⼀块的内容了。简单来说,标记还 是字符串,是构成代码的最⼩单位。这⼀过程会将代码分拆成⼀块块,并给这 些内容打上标记,便于理解这些最⼩单位的代码是什么意思
当结束标记化后,这些标记会紧接着转换为 Node ,最后这些 Node 会根据 不同 Node 之前的联系构建为⼀颗 DOM 树
以上就是浏览器从⽹络中接收到 HTML ⽂件然后⼀系列的转换过程 当然,在解析 HTML ⽂件的时候,浏览器还会遇到 CSS 和 JS ⽂件,这时 候浏览器也会去下载并解析这些⽂件,接下来就让我们先来学习浏览器如何解 析 CSS ⽂件
2. 将 CSS ⽂件转换为 CSSOM 树
其实转换 CSS 到 CSSOM 树的过程和上⼀⼩节的过程是极其类似的
在这⼀过程中,浏览器会确定下每⼀个节点的样式到底是什么,并且这⼀过程其实是很消 耗资源的。因为样式你可以⾃⾏设置给某个节点,也可以通过继承获得。在这⼀过程中, 浏览器得递归 CSSOM 树,然后确定具体的元素到底是什么样式。
如果你有点不理解为什么会消耗资源的话,我这⾥举个例⼦
对于第⼀种设置样式的⽅式来说,浏览器只需要找到⻚⾯中所有的 span 标 签然后设置颜⾊,但是对于第⼆种设置样式的⽅式来说,浏览器⾸先需要找到 所有的 span 标签,然后找到 span 标签上的 a 标签,最后再去找到 div 标签,然后给符合这种条件的 span 标签设置颜⾊,这样的递归过程 就很复杂。所以我们应该尽可能的避免写过于具体的 CSS 选择器,然后对于 HTML 来说也尽量少的添加⽆意义标签,保证层级扁平
3. ⽣成渲染树
当我们⽣成 DOM 树和 CSSOM 树以后,就需要将这两棵树组合为渲染树
在这⼀过程中,不是简单的将两者合并就⾏了。渲染树只会包括需要显示的节点和这些节 点的样式信息,如果某个节点是 display: none 的,那么就不会在渲染树中显示。
当浏览器⽣成渲染树以后,就会根据渲染树来进⾏布局(也可以叫做回流),然后调⽤ GPU 绘制,合成图层,显示在屏幕上。对于这⼀部分的内容因为过于底层,还涉及到了硬 件相关的知识,这⾥就不再继续展开内容了。
21.2 为什么操作 DOM 慢
想必⼤家都听过操作 DOM 性能很差,但是这其中的原因是什么呢?
因为 DOM 是属于渲染引擎中的东⻄,⽽ JS ⼜是 JS 引擎中的东⻄。当我们通过 JS 操作 DOM 的时候,其实这个操作涉及到了两个线程之间的通信,那么势必会带来⼀些性 能上的损耗。操作 DOM 次数⼀多,也就等同于⼀直在进⾏线程之间的通信,并且操作 DOM 可能还会带来重绘回流的情况,所以也就导致了性能上的问题。
经典⾯试题:插⼊⼏万个 DOM,如何实现⻚⾯不卡顿?
对于这道题⽬来说,⾸先我们肯定不能⼀次性把⼏万个 DOM 全部插⼊,这样肯定会造成 卡顿,所以解决问题的重点应该是如何分批次部分渲染 DOM 。⼤部分⼈应该可以想到通 过 requestAnimationFrame 的⽅式去循环的插⼊ DOM ,其实还有种⽅式去解决这个问 题:虚拟滚动( virtualized scroller )。
这种技术的原理就是只渲染可视区域内的内容,⾮可⻅区域的那就完全不渲染了,当⽤户 在滚动的时候就实时去替换渲染的内容
从上图中我们可以发现,即使列表很⻓,但是渲染的 DOM 元素永远只有那么 ⼏个,当我们滚动⻚⾯的时候就会实时去更新 DOM ,这个技术就能顺利解决 这道经典⾯试题
21.3 什么情况阻塞渲染
⾸先渲染的前提是⽣成渲染树,所以 HTML 和 CSS 肯定会阻塞渲染。如果你想渲染的越 快,你越应该降低⼀开始需要渲染的⽂件⼤⼩,并且扁平层级,优化选择器。
然后当浏览器在解析到 script 标签时,会暂停构建 DOM ,完成后才会从暂停的地⽅重 新开始。也就是说,如果你想⾸屏渲染的越快,就越不应该在⾸屏就加载 JS ⽂件,这也 是都建议将 script 标签放在 body 标签底部的原因。
当然在当下,并不是说 script 标签必须放在底部,因为你可以给 script 标签添加 defer 或者 async 属性。
当 script 标签加上 defer 属性以后,表示该 JS ⽂件会并⾏下载,但是会放到 HTML 解析完成后顺序执⾏,所以对于这种情况你可以把 script 标签放在任意位置。
对于没有任何依赖的 JS ⽂件可以加上 async 属性,表示 JS ⽂件下载和解析不会阻 塞渲染。
21.4 重绘(Repaint)和回流(Reflow)
重绘和回流会在我们设置节点样式时频繁出现,同时也会很⼤程度上影响性 能。
- 重绘是当节点需要更改外观⽽不会影响布局的,⽐如改变 color 就叫称为重绘
- 回流是布局或者⼏何属性需要改变就称为回流。
- 回流必定会发⽣重绘,重绘不⼀定会引发回流。回流所需的成本⽐重绘⾼的多,改变⽗节点⾥的⼦节点很可能会导致⽗节点的⼀系列回流。
以下⼏个动作可能会导致性能问题:
- 改变 window ⼤⼩
- 改变字体
- 添加或删除样式
- ⽂字改变
- 定位或者浮动
- 盒模型
并且很多⼈不知道的是,重绘和回流其实也和 Eventloop 有关。
- 当 Eventloop 执⾏完 Microtasks 后,会判断 document 是否需要更新,因为浏览器是 60Hz 的刷新率,每 16.6ms 才会更新⼀次。
- 然后判断是否有 resize 或者 scroll 事件,有的话会去触发事件,所以 resize 和scroll 事件也是⾄少 16ms 才会触发⼀次,并且⾃带节流功能。
- 判断是否触发了 media query
- 更新动画并且发送事件
- 判断是否有全屏操作事件
- 执⾏ requestAnimationFrame 回调
- 执⾏ IntersectionObserver 回调,该⽅法⽤于判断元素是否可⻅,可以⽤于懒加载上,但是兼容性不好 更新界⾯
- 以上就是⼀帧中可能会做的事情。如果在⼀帧中有空闲时间,就会去执⾏requestIdleCallback 回调
21.5 减少重绘和回流
-
使⽤ transform 替代 top
-
使⽤ visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流 (改变了布局)
-
不要把节点的属性值放在⼀个循环⾥当成循环⾥的变量
for(let i = 0; i < 1000; i++) { // 获取 offsetTop 会导致回流,因为需要去获取正确的值 console.log(document.querySelector('.test').style.offsetTop) } -
不要使⽤ table 布局,可能很⼩的⼀个⼩改动会造成整个 table 的重新布局
-
动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使⽤requestAnimationFrame
-
CSS 选择符从右往左匹配查找,避免节点层级过多
-
将频繁重绘或者回流的节点设置为图层,图层能够阻⽌该节点的渲染⾏为影响别的节点。⽐如对于 video 标签来说,浏览器会⾃动将该节点变为图层。
设置节点为图层的⽅式有很多,我们可以通过以下⼏个常⽤属性可以⽣成新图层
will-change
video 、 iframe 标签
⼀个页⾯上有⼤量的图⽚(⼤型电商⽹站),加载很慢,你有哪 些⽅法优化这些图⽚的加载,给⽤户更好的体验。
答:
- 图⽚懒加载,在页⾯上的未可视区域可以添加⼀个滚动事件,判断图⽚位置与浏览器顶端的距离与页⾯的距离,如果前者⼩于后者,优先加载。
- 如果为幻灯⽚、相册等,可以使⽤图⽚预加载技术,将当前展示图⽚的前⼀张和后⼀张优先下载。
- 如果图⽚为css图⽚,可以使⽤ CSSsprite , SVGsprite , Iconfont 、 Base64 等技术。
- 如果图⽚过⼤,可以使⽤特殊编码的图⽚,加载时会先加载⼀张压缩的特别厉害的缩略图,以提⾼⽤户体验。
- 如果图⽚展示区域⼩于图⽚的真实⼤⼩,则因在服务器端根据业务需要先⾏进⾏图⽚压缩,图⽚压缩后⼤⼩与展示⼀致。
网页验证码是⼲嘛的,是为了解决什么安全问题?
答:
- 区分⽤户是计算机还是⼈的公共全⾃动程序。可以防⽌恶意破解密码、刷票、论坛灌⽔
- 有效防⽌⿊客对某⼀个特定注册⽤户⽤特定程序暴⼒破解⽅式进⾏不断的登陆尝试

我比较喜欢的面试者
- 基础扎实
- 从多年的经验看,那些发展好的同学都具备扎实的基础知识
- 比如只懂 jQuery 不懂 JavaScript 是不行的哦
- 如果了解计算机基础会更好,因为我们将面临很多非前端技术的问题
- 主动思考
- 被动完成任务的同学在这里进步会很慢
- 你需要有自己的想法,而不是仅仅完成任务
- 爱学习
- 前端领域知识淘汰速度很快,所以最好能经常学习和接触新东西
- 有深度
- 遇到问题时多研究背后深层次的原因,而不是想办法先绕过去
- 比如追踪某个 Bug 一直了解它本质的原因
- 有视野
- 创新往往来自于不同学科的交集,如果你了解的领域越多,就越有可能有新想法

好啦,本期前端面试题就分享到这里,我们下期见!最后祝愿大家都能顺利拿到大厂offer!
转载地址:http://mglof.baihongyu.com/